Sentiment Analysis: Why Your Model Misses Sarcasm

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What is Sentiment Analysis in Machine Learning?
- How Sentiment Analysis Differs from Text Classification
- Main Sentiment Analysis Methods to Know
- 5 Types of Sentiment Analysis Models
- How to Perform Sentiment Analysis
- Key Challenges That Kill Production Accuracy
- Popular Sentiment Analysis Tools and When to Use Them
- Deploying Sentiment Analysis Models to Production
- What Prevents Sentiment Models from Failed Deployments
- About Label Your Data
- FAQ

TL;DR
- Sentiment analysis models drop from testing benchmarks to production reality due to sarcasm, domain mismatch, and data quality issues.
- The 80% human annotator agreement ceiling limits model performance more than algorithm choice (transformer vs SVM matters less than annotation quality).
- Start with simple baselines (VADER, SVM) before jumping to transformers; prove the complexity is worth the operational overhead for your use case.
What is Sentiment Analysis in Machine Learning?
Your sentiment model achieves 96% accuracy in testing, then drops to 75% in production. Sarcasm breaks it. Domain-specific language confuses it. The neutral category defeats it entirely.
Sentiment analysis classifies text polarity (i.e., positive, negative, or neutral) using machine learning trained on labeled data. For ML engineers building these systems in 2026, the gap between benchmarks and reality is consistent. Research claims rarely survive contact with real-world text.
The difference comes down to data quality, domain specificity, and edge case handling. A model trained on movie reviews fails on financial reports. Twitter-trained classifiers break on support tickets. Poor annotation guidelines create a ceiling at the 80% human agreement rate.
This guide covers what actually works in deployed systems: algorithms, datasets, common failures, and how practitioners close the accuracy gap.
How Sentiment Analysis Differs from Text Classification

NLP for sentiment analysis works differently than standard text classification.
Standard text classification answers “What is this about?” Natural language processing sentiment analysis answers “How does the author feel about this?”
Text sentiment analysis must handle negation ("not good" vs "good"), intensifiers ("very," "extremely"), and context-dependent polarity.
For example, the word "unpredictable" signals positive sentiment for a thriller movie but negative sentiment for car brakes. "Easy to charge" is positive in electronics reviews; "easy to guess" is negative in movie reviews.
This context sensitivity is why general-purpose sentiment analyzers consistently produce what researchers call "unsatisfactory classifications" on specialized domains like healthcare or finance.
Main Sentiment Analysis Methods to Know
Rule-based sentiment analysis
Lexicon-based tools like VADER match words against sentiment dictionaries with pre-assigned polarity scores. Zero training data required, instant results you can explain.
Performance varies by domain. VADER works well on social media but struggles on formal text.
The failure modes are predictable. One GitHub issue documented VADER scoring "no problems ever" and "no complaints" as ~60% negative. The library maintainer explained the root cause: "The problem comes from 'nothing' being considered a negating word that flips valence."
The verdict from practitioners: "You shouldn't use this in production for customer support jobs. Almost no common sense context awareness."
Use this for quick validation or when you need to explain every prediction. Don't use it when accuracy matters more than interpretability.
Machine learning sentiment analysis
Traditional ML approaches (i.e., Naive Bayes, SVM, or Random Forest) combined with TF-IDF vectorization consistently outperform lexicon methods when labeled training data is available. SVM with TF-IDF typically beats rule-based approaches by a significant margin.
The constraint is data. Minimum viable results require 1,000-5,000 labeled samples with balanced class distributions. Document length between 50-150 words optimizes accuracy.
Traditional sentiment analysis machine learning excels when interpretability matters, compute resources are limited, or you need rapid iteration cycles.
Transformer-based approaches
AI for sentiment analysis using transformers, like Fine-tuned BERT, delivers strong accuracy on standard benchmarks. DistilBERT offers the best production tradeoff: same accuracy, 60% faster, 40% smaller.
However, hybrid systems consistently outperform single-approach models in production.
Hybrid approaches win in practice
Combining lexicon features with ML classifiers captures benefits from both approaches. Common patterns include using VADER scores as additional features alongside TF-IDF, or using rules for preprocessing (negation detection, intensifier identification) before feeding to neural networks.
One practitioner combined Random Forest with RoBERTa embeddings and achieved 11x better prediction than random guessing. His key insight: "Context is King. With transformers like BERT/RoBERTa, extensive text cleaning (removing stopwords/punctuation) can actually degrade performance by destroying context."
Instead of relabeling everything, I find the specific spots where things go wrong. My team pulls a batch of weird annotations, sees the pattern, and rewrites just that section of the guidelines. We tackle the trickiest cases first and make a quick video or one-pager for the team. Treat guideline updates as small, manageable fixes.

5 Types of Sentiment Analysis Models
Polarity detection
Binary or three-class classification (positive/negative/neutral) handles high-volume scenarios. This is the most common production use case.
The neutral category defeats everyone. Multiple practitioners identify it as the hardest to classify. As one researcher observed: "Most tools heavily bias towards 'neutral' which really means 'not sure'."
Fine-grained sentiment
Five-star scale classification proves significantly harder: accuracy drops substantially due to ordinal classification challenges and class boundary ambiguity. Use regression or ordinal cross-entropy loss rather than standard classification for better results.
Aspect-based sentiment analysis (ABSA)
Extract sentiment toward specific features: "The battery is great but the screen is terrible" yields battery→positive, screen→negative. State-of-the-art models show meaningful improvements over previous approaches.
The implementation complexity is substantially higher, requiring both aspect extraction and per-aspect sentiment classification.
Emotion detection
Classify text into specific emotions (joy, anger, sadness) using taxonomies like Ekman's 6 basic emotions or Google's GoEmotions with 27 categories. Performance remains challenging due to multi-label complexity.
The multi-label nature and severe class imbalance (rare emotions like grief vs. common emotions like joy) make this significantly harder than polarity detection.
Audio adds another dimension. Case in point, one French conversational AI company was looking for an expert data annotation company to label 4,000 hours of customer support recordings to identify mood solely from voice tone, without language context.
They turned to Label Your Data to assemble a team of 12 annotators from diverse cultural backgrounds. Our data experts helped capture the subtle vocal cues that signal frustration, satisfaction, or confusion in the audio files.
Such nuances vary significantly across geography, gender, and age, which general-purpose models consistently miss.
Intent-based analysis
Predict future behavior (purchase intent, churn signals) from text, combining sentiment with action prediction. These systems typically use multitask architectures with separate sentiment and intent classification heads.
How to Perform Sentiment Analysis
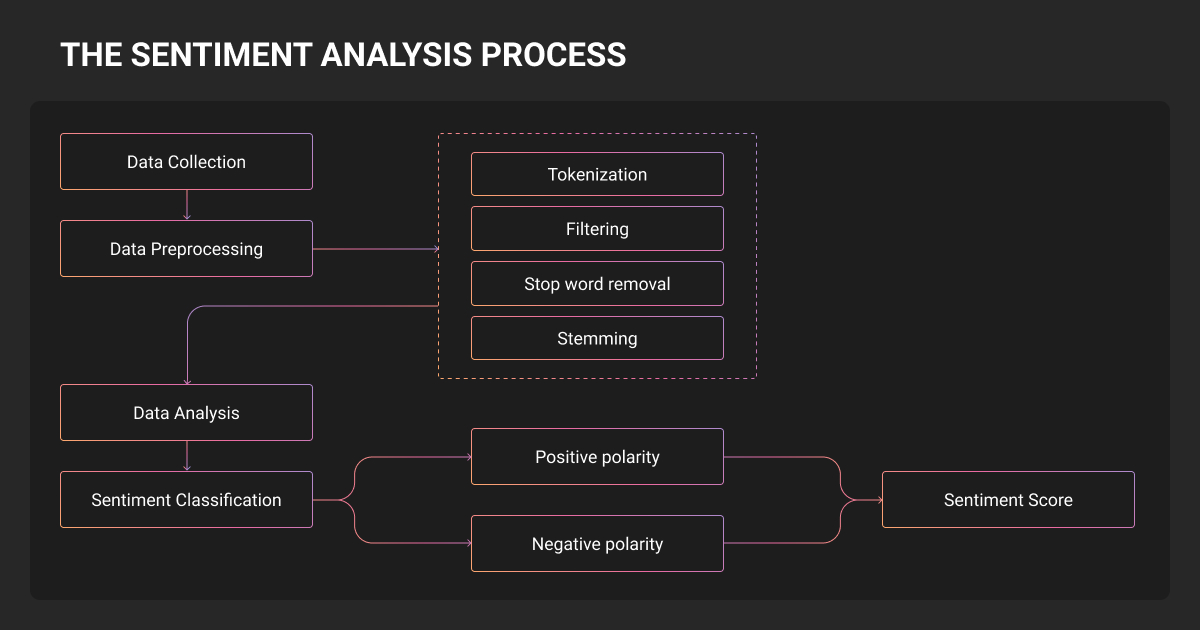
Step 1: Prepare your sentiment analysis dataset
Learning how to do sentiment analysis starts with data quality. It determines your sentiment analysis model ceiling.
Manual sentiment analysis means selecting media, date ranges, and labeling sentiment one by one. Tedious, but this is where model quality is won or lost.
Target Cohen's Kappa ≥ 0.8 for reliable data annotation. Use minimum 3 annotators with guidelines that define boundaries with explicit edge case examples.
Multiple rounds improve results. One of our clients, a UK NLP company processing 2,000-3,000 monthly reviews (1-5 scale), faced difficulties with reviews rated 2-4. This is the ambiguous middle, where annotators disagree most.
We launched multiple labeling rounds with at least two Label Your Data dedicated annotators per review to achieve production precision for the client.
Besides, real-world machine learning datasets skew heavily. Models trained on imbalanced data achieve high accuracy by predicting the majority class while missing minority sentiment entirely.
You can address this through SMOTE for oversampling, weighted cross-entropy for class-balancing, or GPT-4 for synthetic data generation.
One engineer captured the annotation challenge: "I'd badly like an angry toot filter but I'd have to find about 5000 angry toots and 5000 non-angry toots and that is probably about a week's worth of psychologically difficult work."
That week determines whether you hit 70% or 90%. Plus, understanding data annotation pricing upfront helps you budget for the annotation quality your model actually needs.
Step 2: Preprocess Text Data
Sentiment analysis techniques for preprocessing vary by approach.
For traditional ML:
- Apply lowercasing, stemming or lemmatization
- Remove stop words but exclude negation words ("not", "never") and intensifiers ("very", "extremely")
- Use TF-IDF for vectorization
For transformers, preserve more context. BERT handles capitalization internally.
Critical preprocessing steps:
- Expand contractions (essential for negation: "weren't" → "were not")
- Preserve or convert emojis to sentiment tokens (they carry strong signal)
- Apply minimal punctuation cleaning
Over-aggressive preprocessing hurts transformer performance. The model needs context to understand meaning.
Step 3: Train Your Model
Sentiment analysis algorithms selection depends on your constraints:
Naive Bayes
Fast baseline. Training takes seconds, works with high-dimensional text, minimal tuning needed. Good for quick validation or when you need something running today.
SVM
Outperforms Naive Bayes on most benchmarks. Linear kernels work best for text. Sweet spot: 5,000-50,000 samples where deep learning would overfit.
LSTM/BiLSTM
Captures sequential dependencies and context. Requires 10,000+ samples and GPU resources. The context awareness advantage becomes clear with complex linguistic patterns.
BERT and transformers
Best accuracy when you have sufficient data and compute. Fine-tuning needs 3,000-5,000 samples, 2-4 epochs, and learning rates between 2e-5 to 5e-5. Common mistake: using learning rate 1e-3 destroys performance. The BERT authors' range exists for a reason.
One production engineer running BERT classifiers shared: "I have a small Swiss army collection of custom BERT fine tunes that execute document classification tasks in 2.4ms. Find me an LLM that can do anything in 2.4ms."
But benchmark claims rarely survive production. Meltwater processes 450 million documents daily with 20ms latency and achieves 83% accuracy for English, 76% for Chinese. Solid, but far from research paper claims.
Start simple. Prove the complex approach is worth the operational overhead.
Step 4: Evaluate and Iterate
Use Macro F1 as the primary metric for imbalanced sentiment data. It weights all classes equally regardless of size. Accuracy misleads: a dataset with 90% positive samples achieves 90% accuracy by always predicting positive, completely failing on minority classes.
Build confusion matrices to identify systematic failures. Neutral↔positive confusion suggests threshold adjustment. Consistent sarcasm misclassification indicates need for pre-filtering. Negation failures require specific handling modules.
Test asymmetry reveals tool limitations: TextBlob achieves 97.1% accuracy on positive texts but only 22.9% on negative texts; VADER shows better balance at 84.3% positive, 43.5% negative. Data annotation tools help track these performance gaps and flag samples for review.
Production models need feedback loops.
My sentiment model always trips over industry jargon. I’ve found it helps to grab a few examples where it failed and tweak the instructions. We looked at maybe ten tricky customer tickets, adjusted our rules, and the model's accuracy jumped. You don't have to relabel everything, just fix the spots that are breaking.

 CEO, dynares
CEO, dynares
Key Challenges That Kill Production Accuracy
You've trained a sentiment analysis model that works in testing. Then it hits production and breaks.
Here's why:
Sarcasm inverts polarity systematically
"What a great experience, I love waiting 3 hours for support" contains positive words expressing negative sentiment. Models interpret sarcasm literally.
Despite transformer advances, detecting sarcasm remains difficult. BERT/RoBERTa fine-tuned on Reddit's "/s" markers still struggle.
A comprehensive review of the latest NLP techniques for sentiment analysis confirms models still fail on sarcasm, irony, and negation as these challenges persist in state-of-the-art systems.
According to the SarcasmBench research, GPT-4 underperforms supervised fine-tuned smaller models for sarcasm detection. Chain-of-Thought prompting hurts performance.
One of the authors notes: "Sarcasm detection, being a holistic, intuitive, and non-rational cognitive process, does not adhere to step-by-step logical reasoning."
Without proper handling, F1 scores drop dramatically on cross-dataset validation. You can address this through:
- Multitask learning that jointly trains sentiment and sarcasm detection
- Context-aware models that consider previous utterances
- Transformers fine-tuned on sarcasm-annotated datasets
Production systems often pre-filter for sarcasm indicators before classification.
Negation handling requires scope detection
"Not good" should classify as negative, but bag-of-words approaches treat it as two separate tokens, often missing the relationship. The technical challenge extends to determining negation scope: how many words after a negation cue are affected.
NegBERT achieves 88-89% F1 on scope detection. Proper negation handling improves simple classifier accuracy by 5-10 percentage points.
Implementation approaches include:
- Dependency parsing to determine affected words
- Rule-based preprocessing that expands contractions ("weren't" → "were not")
- End-to-end models that jointly learn negation detection and sentiment
Context Dependency Breaks Domain Transfer
"Sick" means terrible in medical reviews, awesome in street slang. "This will be his first and last movie" is negative without negative words.
Domain-specific fine-tuning isn't optional. General-purpose models fail on specialized domains.
For financial sentiment, fine-tuned RoBERTa significantly outperforms BloombergGPT. SentiCR for code reviews performs well where general tools struggle.
Language and cultural context add complexity. This is why a US company turned to our team at Label Your Data for professional sentiment analysis services. They needed region-specific annotators from Latin America and North Africa to analyze 8,000 French and Spanish social media posts monthly.
We helped them capture native slang, detect irony, and eliminate cultural bias. Because these are the elements that general multilingual models miss.
Imbalanced datasets bias predictions
Production datasets rarely match training distributions.
The model defaults to majority class predictions, missing the minority sentiment you actually need to detect. Monitor class distribution drift and retrain when production data skews differently than training data.
The human ceiling limits model performance
With annotator agreement at 80%, a model achieving 83% is performing near human level.
Inter-annotator agreement directly limits achievable accuracy. Clear definitions of positive, negative, and neutral boundaries with explicit edge case examples improve agreement rates.
Giskard, an ML testing platform, emphasizes: "Collecting domain feedback on the model is critical for a robust deployment and avoiding nasty surprises at production time."
When we see the model tripping over domain-specific issues like sarcasm in a particular community, or jargon that skews polarity, we adjust the guidelines in small, deliberate steps. We pull 5-10% of the trickiest items and run them back through annotation QA. We only re-annotate a few hundred samples that sit in those gray areas, using the refined rules.
 Developer, Founder, TwinCore
Developer, Founder, TwinCore
Popular Sentiment Analysis Tools and When to Use Them
NLTK VADER
Social media prototyping. Zero training, sub-millisecond inference. As one ML practitioner notes, VADER works best "if sentiment was absolutely the only thing you planned to do with this text, and need it processed as fast as possible."
spaCy
Production-ready NLP pipelines. Requires training a TextCategorizer from scratch. Integration with Hugging Face transformers (spacy-transformers) enables transformer-based sentiment with efficient pipeline architecture.
Hugging Face transformers
Hundreds of sentiment models. General-purpose (siebert/sentiment-roberta-large-english) to domain-specific (FinancialBERT-Sentiment-Analysis). Run inference with one line of code using the pipeline("sentiment-analysis") function.
Cloud APIs
These include Google Cloud NLP, AWS Comprehend, and Azure Text Analytics. Quick deployment, no ML expertise needed. Limited customization. Pricing per 1,000 text records with free tiers.
Choose cloud APIs when data privacy permits and time-to-market matters more than per-inference cost. At scale, self-hosted models cost less.
Deploying Sentiment Analysis Models to Production
Build vs. buy depends on data privacy, volume economics, and customization needs. For domain-specific applications, fine-tuned transformers outperform general cloud APIs.
Monitor for data drift (vocabulary coverage, unknown tokens), prediction drift (output distribution changes), and business metric correlation. Implement feedback loops, track confidence distributions, sample predictions for review.
Common applications of sentiment analysis include customer feedback analysis, social media monitoring, support ticket routing, and market research.
What Prevents Sentiment Models from Failed Deployments
Start with baselines
VADER for social media, TextBlob for quick prototyping, then TF-IDF + SVM. When accuracy justifies complexity, fine-tune DistilBERT with 3,000-5,000 labeled samples.
Prioritize data quality
Algorithm choice here matters less than annotation quality. Clear guidelines, multiple annotators, regular agreement checks, explicit edge case handling. Every model hits a ceiling set by training data quality. Better algorithms can't fix bad data.
Evaluate and monitor
Use Macro F1 instead of accuracy. Build error analysis workflows. Monitor for drift. Test synonym invariance and negation sensitivity before deployment.
The gap between benchmarks and production comes from domain mismatch, data quality issues, and uncovered edge cases. Most ML engineers chase architectures when the real bottleneck sits in training data.
Label Your Data helps ML teams close that gap with:
- Clear annotation guidelines that handle edge cases
- Multiple annotator review with quality control processes
- Inter-annotator agreement checks that actually improve your model ceiling
Better sentiment data beats better sentiment models every time.
About Label Your Data
If you choose to delegate sentiment data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is meant by sentiment analysis?
Sentiment analysis is computational identification of opinions and emotions in text using machine learning models trained on labeled data. It classifies text polarity as positive, negative, or neutral.
What are the three types of sentiment analysis?
The three main types of sentiment analysis are polarity detection (positive/negative/neutral), aspect-based sentiment analysis (sentiment toward specific features), and emotion detection (joy, anger, sadness, etc.).
What are the four main steps of sentiment analysis?
The four steps in sentiment analysis are: (1) data collection and labeling, (2) preprocessing (tokenization, cleaning, normalization), (3) feature extraction and model training, and (4) evaluation and iteration based on production feedback.
How does sentiment analysis work in AI?
AI sentiment analysis uses supervised machine learning models trained on labeled text examples. The model learns patterns that distinguish positive from negative sentiment, then applies those patterns to classify new text.
Can ChatGPT do sentiment analysis?
Yes, but ChatGPT isn't trained for specific domains. It performs better than traditional ML models on general text but costs more and has higher latency. For production systems, practitioners train smaller student models from LLM weak labels for deployment.
What is sentiment analysis used for?
Customer feedback analysis (product reviews, NPS), social media monitoring (brand reputation), support ticket routing (priority detection), and market research (competitor analysis, trend detection).
What model does NLP use for sentiment analysis?
NLP sentiment analysis models depend on requirements. Naive Bayes and SVM for fast baselines, LSTM/BiLSTM for context-aware classification, BERT/RoBERTa/DistilBERT for state-of-the-art accuracy.
DistilBERT offers the best production tradeoff for sentiment analysis NLP: strong performance with faster inference than BERT-base.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.