OCR Data Entry: Preprocessing Text for NLP Tasks

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Why OCR Data Entry Needs Preprocessing for NLP
- OCR Data Entry Errors That Impact NLP Models
- Preprocessing OCR Text Before Feeding It to NLP
- Tokenization and Normalization for OCR Data Entry
- Tools That Support OCR Data Entry Preprocessing
- Scaling OCR Data Entry in NLP Pipelines
- Final Tips Before You Build Your Pipeline
- About Label Your Data
- FAQ

TL;DR
- OCR gives you raw text, but without preprocessing, it won’t work well in NLP pipelines.
- Broken formatting, missing punctuation, and lost structure often go unnoticed but damage performance.
- Classification, entity recognition, and parsing all suffer when fed noisy OCR output.
- Combining basic cleaning with layout-aware tools is key to producing usable text.
- To scale reliably, build modular pipelines and track quality using CER, WER, or entropy.
Why OCR Data Entry Needs Preprocessing for NLP
AI data entry gives you text, but not text you can trust. Most outputs are messy, fragmented, and stripped of structure. If you send that directly to an NLP model, you’ll get unpredictable results. That’s why the data entry step between OCR and NLP matters. You need to fix what the OCR engine can’t.
So, what does OCR stand for in data entry processes? OCR means Optical Character Recognition. In data entry workflows, it refers to converting scanned or printed documents into machine-readable text. But that output isn’t always clean or usable, especially for NLP tasks.
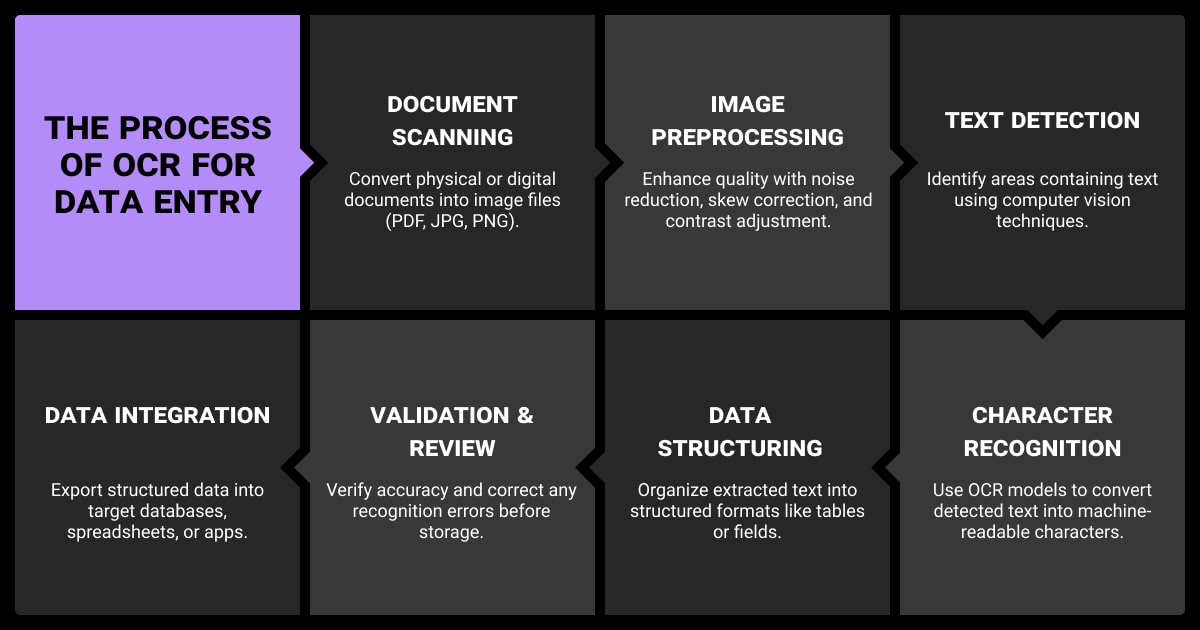
What OCR Output Looks Like (and Why It’s Problematic)
OCR data extraction focuses on character recognition, not meaning. Even more advanced approaches like intelligent character recognition often struggle with formatting or layout consistency in low-quality scans.
Even the best OCR data entry software returns raw strings with no sense of formatting. You’ll often see:
- Words split across lines, like
engi- neer - Names or fields jammed together:
JohnDoe - Lost line breaks and missing bullets
- Random characters or misread punctuation
- Tables flattened into unreadable blocks
This happens even with good scans. Poor-quality inputs only make it worse, especially compared to tasks like image recognition, where the structure isn't text-dependent. OCR does its part, but it doesn’t clean up after itself.
How Bad Input Breaks Downstream NLP Tasks
NLP models aren’t built for messy input. They expect something close to natural language. When the structure is gone, your pipeline suffers.
- Entity recognition misses names and addresses
- Classification models overfit on noisy tokens
- Parsing fails when forms lose their key-value format
- Summarization tools pull in duplicated or broken lines
And since the models still return results, you might not notice the damage right away. But the accuracy drops, and debugging takes longer than cleaning would have. That’s why OCR data entry needs preprocessing. You’re not just cleaning text. You’re making it usable.
OCR Data Entry Errors That Impact NLP Models
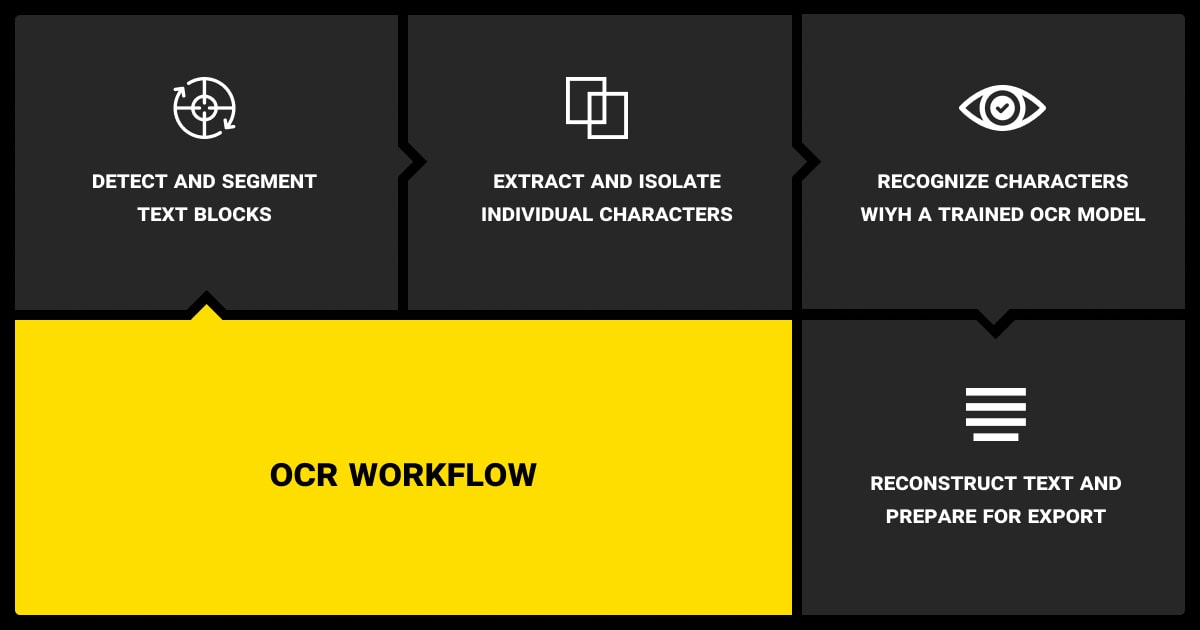
Once OCR has done its job, the errors it leaves behind aren’t always obvious. But they quietly break downstream tasks. The model predictions still come out, so nothing crashes, but the quality falls apart.
Sentence Structure and Entity Breakage
OCR often splits sentences in odd places or merges lines that shouldn’t go together. Common issues include:
- Mid-word line breaks, especially from PDFs with hyphenation
- Lowercased sentence starts and dropped punctuation
- Inconsistent spacing between words or within names
This throws off models that rely on clean tokens and breaks down when OCR algorithms fail to preserve sentence structure. Entity recognition is especially sensitive. If an address or person’s name is split or merged, it won’t be tagged correctly. Even slight formatting inconsistencies can shift token positions enough to misalign annotations during training. This becomes more common in OCR pipelines dealing with cursive text or forms, where AI handwriting recognition introduces additional spacing and segmentation noise.
Layout Loss and Structural Flattening
Many scanned documents follow a layout that adds meaning: forms, tables, bullet lists, and section headers. OCR usually flattens all of that. What you get is:
- Column data turning into unreadable text blocks
- Label-value pairs losing their alignment
- Sections running into each other with no clear break
This is a problem for anything that relies on spatial structure. For example, form parsers looking for key-value patterns will fail if the layout is gone. Table extraction becomes impossible without extra heuristics or layout models. In longer documents, summarization and segmentation also degrade because the original logic of the content is lost.
The model can’t guess what the structure used to be. If it’s important to your machine learning dataset, you have to restore it.
Preprocessing OCR Text Before Feeding It to NLP
Document digitization with OCR is about removing ambiguity and restoring enough structure for your NLP model to work as expected. The level of preprocessing depends on your task, but most workflows include a mix of basic and high-level fixes.
Basic Cleaning: De-Hyphenation, Punctuation, Whitespace
Start with the obvious stuff:
- Remove hyphens at line breaks (e.g.,
infor- mationbecomes information) - Fix irregular spacing and collapsed words
- Normalize punctuation: restore missing periods, commas, colons
- Drop repeated headers and footers that appear on every page
These can be handled with regex or simple string-processing scripts. For some pipelines, this is enough to get acceptable performance. But often, especially for document-level NLP tasks, it only scratches the surface.
High-Level Denoising Using Language Models
If the text is badly degraded or inconsistent, consider using lightweight language models for denoising. Especially if your pipeline includes LLM data labeling tasks. These models can:
- Predict missing tokens in context
- Replace out-of-vocabulary artifacts
- Reconstruct plausible sentence boundaries
You don’t need a full transformer or external LLM fine-tuning services for this. A distilled BERT or custom masked LM, or models fine-tuned with OCR deep learning datasets, can clean up the input before downstream tasks. They can also support LLM fine tuning.
That said, denoising models can also hallucinate. You’ll need to validate outputs, especially if the downstream use is sensitive.
Handling Structure When It Matters (Tables, Forms, Layout)
When your task depends on layout, like key-value extraction or table parsing, data entry OCR output can't be treated as flat text. In those cases:
- Use document layout analysis tools (like
pdfplumberorlayoutparser) to segment by blocks - Reconstruct tables using bounding boxes from OCR output, not just text order
- Preserve spatial relations in metadata if your downstream model can consume them
If structure matters and you lose it during OCR, preprocessing becomes a recovery job. And it’s usually cheaper to do this early than to try training models to work around it.
The breakthrough came from applying adaptive thresholding and morphological operations for denoising and contrast enhancement. These steps dramatically cleaned up inputs before OCR.

 Co-Founder & CTO, SmythOS.com
Co-Founder & CTO, SmythOS.com
Tokenization and Normalization for OCR Data Entry
Once the OCR text is cleaned up, it still needs to be tokenized and normalized. These steps seem minor but have a big impact, especially when OCR artifacts distort what a tokenizer expects.
Choosing Tokenizers That Handle OCR Artifacts
Not all tokenizers perform well on noisy or inconsistent input. WordPiece and SentencePiece tokenizers, for example, often split words in unexpected ways when spacing or punctuation is off.
What helps:
- Pre-tokenizing with custom rules before applying model tokenization
- Using byte-level models like GPT-style tokenizers that are more forgiving to noise
- Applying consistent lowercasing, unicode normalization, and digit grouping before tokenization
The goal is to reduce the number of unexpected tokens that don’t match the vocabulary your model was trained on. The more mismatches you get, the worse your model performs.
Normalization for Multilingual or Domain-Specific Text
OCR errors increase with uncommon scripts, low-resource languages, or technical documents. Normalization becomes essential here.
For multilingual pipelines:
- Normalize unicode variants (e.g., accented vs unaccented forms)
- Map OCR-prone confusions, like Cyrillic and Latin characters
For technical domains:
- Clean up unit markers, equation formatting, or custom abbreviations
- Use dictionaries or lookup tables to standardize critical entities
In some projects, it even makes sense to insert a normalization layer trained on synthetic OCR errors — especially if you expect the same types of noise across your data.
Tokenization and normalization may seem routine, but for OCR and data entry services feeding NLP systems, these are not optional. They’re what makes the output predictable.
The combination of visual preprocessing and language-specific models consistently delivers superior results. In our work with bilingual archival footage, adaptive thresholding significantly improved subtitle extraction from noisy backgrounds.
 Founder, Caption Easy
Founder, Caption Easy
Tools That Support OCR Data Entry Preprocessing
There’s no single tool that cleans OCR output perfectly. You’ll likely need to mix open-source libraries, simple scripts, and commercial APIs depending on the structure and quality of your data.
Open-Source Stacks for Custom Pipelines
If you want control, start with these:
- Python + Regex + spaCy
Use regex for basic cleanup, then spaCy for tokenization, sentence splitting, and light entity cleanup. - pdfplumber or PyMuPDF
For documents with layout, these extract not just text but positioning data to help reconstruct structure. - layoutparser
Useful for segmenting text blocks based on visual layout, especially in scanned forms or multi-column PDFs. - CleanEval, trankit, or rule-based heuristics
These help with sentence boundary recovery and domain-specific corrections.
The upside is flexibility. The downside is time; you’ll need to fine-tune your pipeline to each document type.
Commercial APIs That Offer Postprocessing Options
Some OCR software for data entry include built-in text cleanup or postprocessing options. These can help when you’re scaling fast or working with documents in multiple languages.
- Google Cloud Vision and ABBYY both offer structured outputs, including detected languages and bounding boxes.
- Amazon Textract adds key-value pairs and layout tags you can use to reconstruct forms.
- Microsoft Read API offers paragraph and table detection with JSON outputs.
Most commercial tools are better at structured documents than free engines, but they still produce inconsistent text. If you go this route, treat their output as a starting point, not the final input for NLP.
In practice, combining OCR automated data entry with domain-specific rules gives you the best balance between cost and quality.
Scaling OCR Data Entry in NLP Pipelines

A one-off script might work for a small batch. But if you’re building a production pipeline, your OCR preprocessing needs to scale — both in volume and complexity.
Modular vs End-to-End Architectures
Some teams try to build a single pipeline that goes from scanned document to model output. Others split each step: OCR, clean-up, structure recovery, NLP.
Modular pipelines are easier to debug and swap out:
- You can improve the OCR stage without retraining the NLP model
- Preprocessing can be tuned for specific document types
- Failures are easier to isolate and fix
End-to-end systems reduce latency but make customization harder. They’re better suited for narrow domains or high-volume use cases where flexibility matters less.
There’s no universal answer. It depends on how diverse your documents are, how much control you need, and how often your inputs change.
Batch vs Streaming OCR Pipelines
If you're processing millions of documents — often the case in large-scale data collection services — batching is more efficient:
- Run OCR and cleaning as offline jobs
- Save preprocessed text for faster model inference
Streaming pipelines work better for real-time systems:
- Scan, clean, and parse in near real-time
- Useful for forms, ID processing, or document chatbots
Choose based on latency requirements and infrastructure. Just make sure preprocessing doesn’t become a bottleneck.
Evaluating Output: CER/WER, Entropy, Drop-Offs
How do you know if preprocessing is working?
Some quick metrics:
- CER/WER (Character/Word Error Rate): Compare against clean ground truth
- Entropy: Look for spikes in token distribution that may signal input noise
- Drop-off rates: Check where model predictions degrade across document sections
You just need reliable text that your machine learning algorithm — or your text annotation services — can learn from or infer on. Clean input reduces data annotation overhead, model retraining, and production surprises. It also lowers data annotation pricing by reducing the need for manual correction or relabeling caused by OCR errors.
Final Tips Before You Build Your Pipeline
OCR gives you text. NLP needs clean input. The gap between those two steps — that’s where most teams get stuck.
If your OCR data entry process stops at extraction, you’ll spend more time debugging models than improving them. Preprocessing isn’t glamorous, but it’s where quality starts.
What works:
- Clean up artifacts early
- Restore structure when it matters
- Choose tools that match your document types
- Keep your pipeline modular, so you can adapt as things scale
Whether you're building classification systems, entity extractors, or parsing pipelines, the lesson is the same: bad input costs you more later. Do the cleanup first. Teams without internal capacity often turn to a data annotation company to handle the cleanup and structuring work that OCR pipelines leave behind.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What does OCR stand for?
OCR stands for Optical Character Recognition. It's the technology used to extract text from images or scanned documents. The extracted text can be fed into data pipelines, including NLP applications, once it’s been cleaned and structured properly.
What is OCR data capture?
OCR data capture goes beyond plain text extraction. It includes identifying structured elements like form fields, tables, or key-value pairs from documents. This is especially important for downstream tasks like parsing, classification, or entity extraction, where layout and structure matter.
Is there a free OCR program?
Yes, several free OCR tools exist. Tesseract is the most widely used open-source OCR engine. While it works well for many use cases, its output may require more postprocessing compared to commercial options. Tools like pdfplumber and layoutparser can be used alongside Tesseract for better results.
What is the best software for data entry?
There’s no single best OCR software for data entry. It depends on your documents and how you plan to use the output. For full control, open-source tools like Tesseract and Python-based cleaning scripts are reliable. If you need structured output at scale, APIs like Google Cloud Vision or Amazon Textract offer layout-aware results. For teams that want a done-for-you approach, Label Your Data’s data entry services handle everything from OCR to clean, NLP-ready text through secure data annotation services.
Is Microsoft OCR free?
Yes. Microsoft offers free OCR capabilities through the Windows Media OCR API and as part of tools like OneNote. For developers, the Azure Cognitive Services Read API provides OCR functionality, though it requires a paid tier for high-volume use.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.