Semi Supervised Learning: Best Practices for Model Training

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Why Semi Supervised Learning Matters Today
- Core Assumptions Behind SSL Models
- Choosing the Right Approach in Semi Supervised Learning
- Popular Techniques and How They Work
- When (Not) to Trust Unlabeled Data
- Best Practices to Train Robust SSL Models
- Labeling Strategy for Semi Supervised Learning
- Scaling Semi Supervised Learning to Production
- About Label Your Data
- FAQ

TL;DR
- Semi-supervised learning (SSL) helps you train better models when labeled data is limited, but it’s not plug-and-play.
- SSL works best when your data meets certain conditions: label smoothness, natural clusters, and clear low-density regions.
- Techniques like FixMatch, Mean Teacher, MixMatch, and pseudo-labeling each have tradeoffs.
- For best results, you’ll need to carefully tune loss functions, confidence thresholds, and guard against confirmation bias.
- Production-ready SSL requires monitoring for distribution drift and filtering unlabeled data for quality.
Why Semi Supervised Learning Matters Today
High-quality labeled data is expensive, especially in fields like medical imaging, legal document analysis, or geospatial mapping. But chances are you have plenty of unlabeled data sitting around. Semi supervised learning, or SSL, helps bridge that gap.
When supervised learning runs into data scarcity and unsupervised learning lacks precision, SSL offers a middle ground. It lets you stretch a small labeled set into something more powerful, often approaching the performance of fully supervised models at a fraction of the labeling cost.
What Is Semi Supervised Learning?
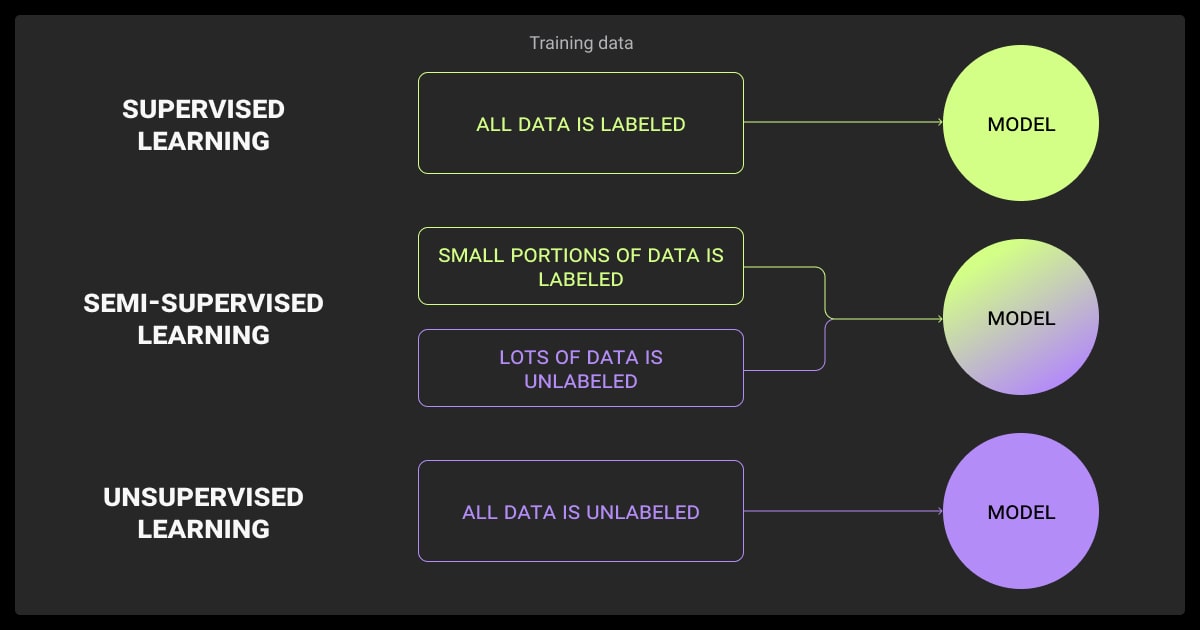
Semi-supervised learning is a machine learning approach that combines a small amount of labeled data with a large amount of unlabeled data during training. It sits between supervised learning (which relies entirely on labeled data) and unsupervised learning (which uses none).
The key idea is to use the labeled data to guide the model, and then leverage patterns in the unlabeled data to improve accuracy. This approach is especially useful when labeling data is costly or time-consuming.
Common in image recognition, natural language processing, and fraud detection, semi-supervised learning helps build more effective models with fewer labeled examples.
Self-Supervised Learning vs Semi Supervised Learning
Both approaches reduce your reliance on data annotation to speed up LLM fine tuning. SSL uses a small set of manually labeled data and a large set of unlabeled data. The model uses the labeled portion to guide its in-context learning.
Self-supervised learning creates labels for the machine learning dataset itself. This saves a lot of time.
When thinking about supervised vs. unsupervised learning, you need to consider how accurate you want the model to be. Is the information easy to label? If you have a more complex project or need high accuracy transfer learning, you might want to look into SL.
If you’re not sure, consider consulting a company that offers comprehensive data and video annotation services. They’ll also assist with data collection services and machine learning model training.
Core Assumptions Behind SSL Models
SSL relies on assumptions about data structure that don’t always hold in real-world datasets.
Smoothness and Cluster Assumption
Semi supervised machine learning often assumes that similar inputs should produce similar outputs, especially when they’re close in feature space.
That’s the smoothness assumption. It’s paired with the cluster assumption; data naturally forms groups, and decision boundaries should avoid slicing through them.
Manifold and Low-Density Separation Assumption
Another core idea is that data lies on a lower-dimensional manifold inside a high-dimensional space. Good semi-supervised machine learning techniques try to learn this manifold and separate classes along regions of low data density.
This avoids decision boundaries that cut through dense, ambiguous areas.
Why Assumptions Break in Real-World Data
In practice, your data won’t always play nice. Think blurry photos, noisy logs, or sarcastic customer feedback that break the smoothness and clustering assumptions.
That’s when SSL can start making confident, but incorrect, predictions. Understanding where your data violates these assumptions is key to applying SSL safely.
We cut our budget for labeling data by more than 80%, and our models still did better than fully supervised ones in production. Semi-supervised learning wasn’t just a quick fix; it became the foundation of our model lifecycle.

 Owner, Weidemann.tech
Owner, Weidemann.tech
Choosing the Right Approach in Semi Supervised Learning
Different SSL methods have different tradeoffs. Choose based on your task, data, and scale needs.
Wrapper Methods
These sit on top of existing supervised models. The idea is simple, let the model generate labels for the unlabeled data it’s confident about, then retrain using those predictions.
It can work well, but errors early in self training semi supervised learning can snowball if bad pseudo-labels reinforce themselves.
Intrinsic SSL Models
These methods are built specifically for SSL. Semi-supervised SVMs (S3VMs) adjust the margin to factor in unlabeled data, while graph-based methods propagate label information over similarity graphs.
They’re theoretically elegant but usually struggle to scale beyond small or medium-sized datasets due to computational cost.
Hybrid Architectures & Multi-Stage Pipelines
In practice, teams often blend approaches: start with pseudo-labeling, add consistency regularization (like Mean Teacher), and sprinkle in active learning to prioritize labeling high-value samples.
Your choices depend on the data modality, task complexity, and compute constraints.
Popular Techniques and How They Work
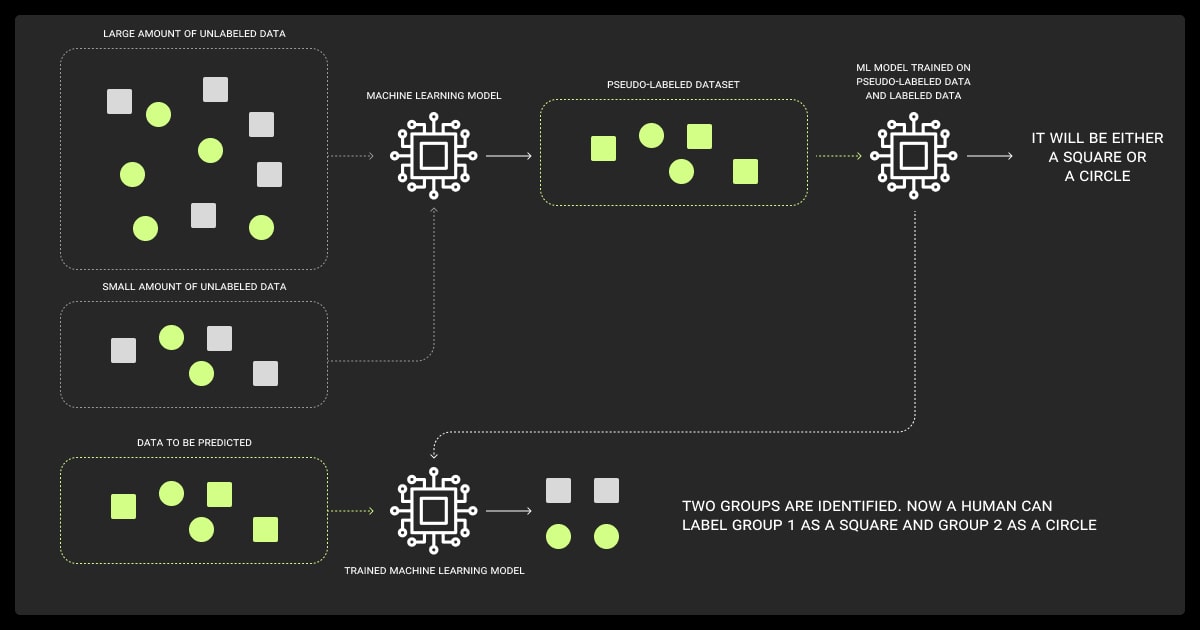
Let’s look at how you can make sure that your semi-supervised learning with deep generative models work.
Consistency Regularization (FixMatch, Pi-Model)
The logic here is simple: a model should give similar predictions when the input is slightly perturbed. The Pi-model uses this directly.
FixMatch takes it further, applying strong augmentations and training only on predictions that stay confident even after perturbation. This filters out noisy guesses and improves label quality.
Pseudo-Labeling and Confidence Thresholds
Here, the model labels its own data, but only keeps predictions above a certain confidence level. Threshold tuning is critical.
Set it too low, and you inject noise; too high, and you throw away useful data. Class-conditional thresholds or adaptive schedules often yield better results.
MixMatch, ReMixMatch, and Data Augmentations
MixMatch fuses labeled and unlabeled samples via data augmentations, interpolations (like MixUp), and guess sharpening.
ReMixMatch expands on this by aligning distributions between labeled and unlabeled data and enforcing augmentation anchoring. Strong augmentations like CutMix, CTAugment, or RandAugment are central to these methods’ success.
We used a Mean Teacher approach to guide our student model on unlabeled data through consistency regularization. Data augmentation techniques like paraphrasing expanded our dataset 3–4x without extra labeling cost.
 President, Kell Solutions
President, Kell Solutions
When (Not) to Trust Unlabeled Data
Unlabeled data can hurt your model if it drifts from the labeled distribution or reinforces errors.
Distribution Mismatch and Label Drift
Unlabeled data only helps if it matches your labeled distribution. If your labels come from North America but your new data is from Asia, that mismatch can mislead your model.
Even gradual shifts, like evolving customer behavior, can degrade performance if left unchecked. Regular drift checks are non-negotiable.
Confirmation Bias in Self-Training
SSL can fall into the trap of amplifying its own errors, especially early in training. A wrong label can reinforce itself across epochs.
You can mitigate this by using ensemble predictions, uncertainty-aware filtering, or teacher-student setups with exponential moving averages (e.g., Mean Teacher).
Evaluating Unlabeled Data Quality
Not all unlabeled data is equally useful. Some samples confuse the model more than they help.
Techniques like entropy-based filtering, kNN similarity to labeled examples, or active learning with uncertainty sampling can highlight which samples to trust, or prioritize for human labeling.
Best Practices to Train Robust SSL Models
Want your semi-supervised learning algorithms to behave as well as possible? Go through these tips.
Balancing Labeled and Unlabeled Loss Terms
Semi supervised learning usually optimizes two loss terms: supervised loss on labeled data and unsupervised loss on pseudo-labeled data.
If you weigh the latter too heavily too soon, noise dominates. Many successful pipelines ramp up the weight on the unsupervised term slowly, based on model confidence or training step.
Choosing and Updating Confidence Thresholds
One-size-fits-all thresholds rarely work. Track confidence per class and over time. Tools like temperature scaling or calibration layers can help you interpret probabilities more reliably.
In some setups, uncertainty-aware losses or dynamic threshold schedules work better than static rules.
Avoiding Feedback Loops with Weak Labels
Don’t let the model train blindly on low-quality pseudo-labels. Ensemble disagreement, dropout-based uncertainty (e.g., MC Dropout), and prediction variance tracking can help flag samples that need human review or further scrutiny.
We run iterative loops: train, sample low-confidence predictions, label, repeat. Instead of labeling data at random, the model flags its most uncertain examples—those are the golden tickets.

Labeling Strategy for Semi Supervised Learning
You can use these tips from data annotation services as a basis for semi supervised learning algorithms for different types of LLMs.
Not sure where to start? You can partner with a data annotation company to give your machine learning algorithm the best possible start.
Otherwise, check out these LLM data labeling tips you can use on your own.
How Many Labels You Actually Need
There’s no magic number, but many SSL setups perform surprisingly well with just 5–10% of the full dataset labeled.
Start small, validate often, and expand your labeled set only when additional labels drive measurable gains.
Using Active Learning to Expand the Labeled Set
Active learning helps you label the most valuable data first. Strategies like uncertainty sampling, margin sampling, or expected gradient length can pinpoint examples that reduce model uncertainty or improve decision boundaries.
Bootstrapping from Domain-Specific Knowledge
Domain heuristics, like regexes in legal docs or expert rules in medicine, can serve as high-precision seeds. Even if they don’t cover everything, they can guide early model behavior and improve pseudo-label accuracy in those first few training cycles.
If you're working with a limited budget, comparing data annotation pricing across vendors can help you decide how much to label up front versus relying on SSL.
Scaling Semi Supervised Learning to Production
To use semi supervised learning in production, you need monitoring, validation loops, and a plan for continuous learning.
Iterative Label Expansion and HITL
Don’t treat SSL as a one-shot process. Build a loop: label a small set, train with SSL, review edge cases, and repeat. Human-in-the-loop review of edge samples or low-confidence predictions keeps errors from compounding across iterations.
Monitoring for Drift and Confidence Collapse
Watch for signs that your model is losing touch with reality, like a collapse in prediction confidence, entropy drops, or class imbalance shifts. Distribution monitoring tools and statistical drift tests (e.g., KL divergence or population stability index) help flag issues early.
Deployment Patterns for SSL in Production Pipelines
SSL can work in both batch and streaming systems. Batch workflows retrain on a schedule with freshly pseudo-labeled data.
Streaming systems require real-time updating, confidence recalibration, and robust pseudo-label acceptance logic. Whatever your setup, track key metrics like pseudo-label precision, class coverage, and prediction entropy.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is an example of a semi-supervised learning model?
FixMatch is a widely-used semi-supervised learning example. It’s a framework that combines pseudo-labeling with consistency regularization. It performs well on datasets like CIFAR-10 and STL-10, especially in low-label regimes.
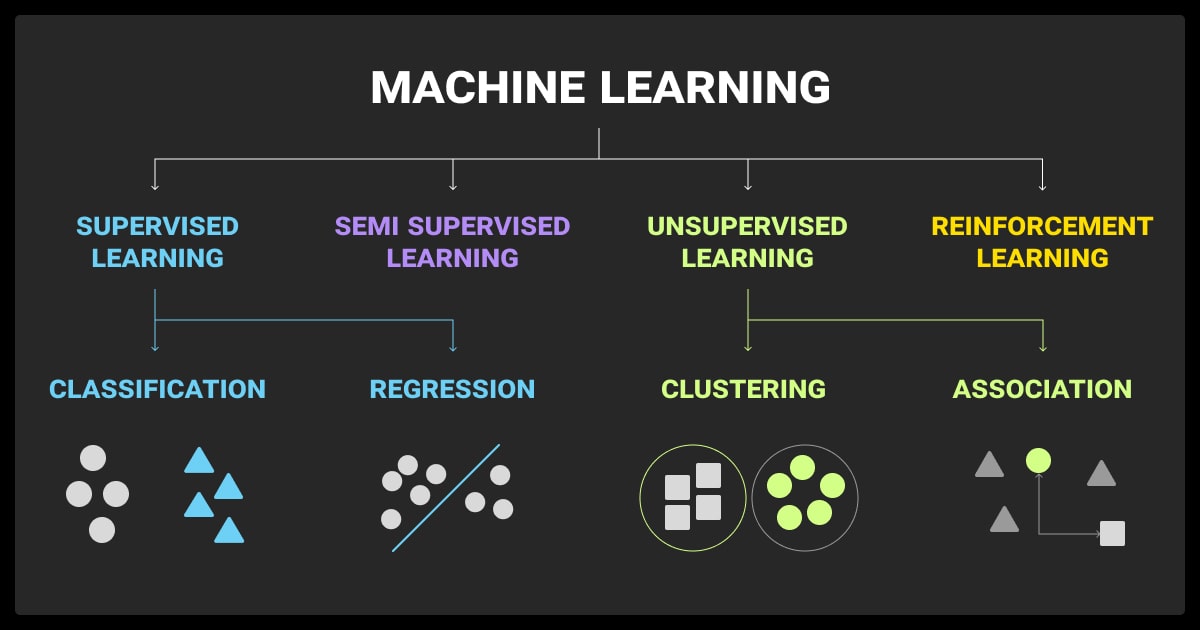
What are the 4 types of ML?
There are four types of machine learning. Supervised learning uses labeled data to train models. Unsupervised learning finds patterns in unlabeled data. Semi-supervised learning combines a small amount of labeled data with a larger unlabeled set. Reinforcement learning trains models through interaction with an environment using rewards and penalties.
What is the difference between unsupervised and semi-supervised learning?
Unsupervised learning works solely on unlabeled data to find structure (e.g., clustering). SSL leverages a small amount of labeled data to guide learning, often yielding better performance on downstream tasks.
How do you validate a semi-supervised model effectively?
Always use a separate, clean, labeled validation set. Track supervised loss, monitor how pseudo-labels evolve over training, and compare predictions across different training snapshots or teacher models.
Is SSL production-ready for real-time systems?
It can be. Fraud detection, spam filtering, and content moderation already use SSL in live settings. For high-stakes domains like healthcare, real-time SSL is possible, but requires strong safeguards, calibrated uncertainty estimates, and ongoing monitoring.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.