Autonomous Vehicle Data Collection: Sensors, Formats, and Tools

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Core Challenges in Autonomous Vehicle Data Collection
- The Sensor Stack Behind Autonomous Vehicle Data Collection
- Data Formats in Autonomous Vehicle Pipelines
- Tools for AV Data Collection and Synchronization
- Inside the Autonomous Vehicle Data Collection Workflow
- Security and Compliance in Autonomous Vehicle Data Collection
- Scaling Up Your AV Data Collection Without Burning Out Your Team
- About Label Your Data
- FAQ

TL;DR
- AVs depend on a constant stream of high-frequency, multi-sensor data, from LiDAR to cameras to radar, to make sense of the road.
- Clean, usable data starts with solid sensor calibration, good conditions, and reliable logging systems.
- Engineers need a full stack of tools to turn messy raw data into something training-ready (e.g., onboard logging to cloud-based QA).
- Bad weather, dropped frames, or misaligned timestamps can silently corrupt your dataset.
- Early QA and smart filtering help prevent wasted annotation effort and broken models.
Core Challenges in Autonomous Vehicle Data Collection
Big data and autonomous vehicles go hand in hand. AV models are only as good as the data we feed them. And it’s not easy to get that data in the real world. Every drive collects a mountain of raw sensor output, along with unpredictable conditions, calibration drift, and the occasional hardware hiccup that can wreck your dataset.
Which means you need to consider autonomous vehicle data collection techniques very carefully before you start working on your machine learning algorithm. If you want to see how this works in practice, check our Formula Student case study for a real-world example.
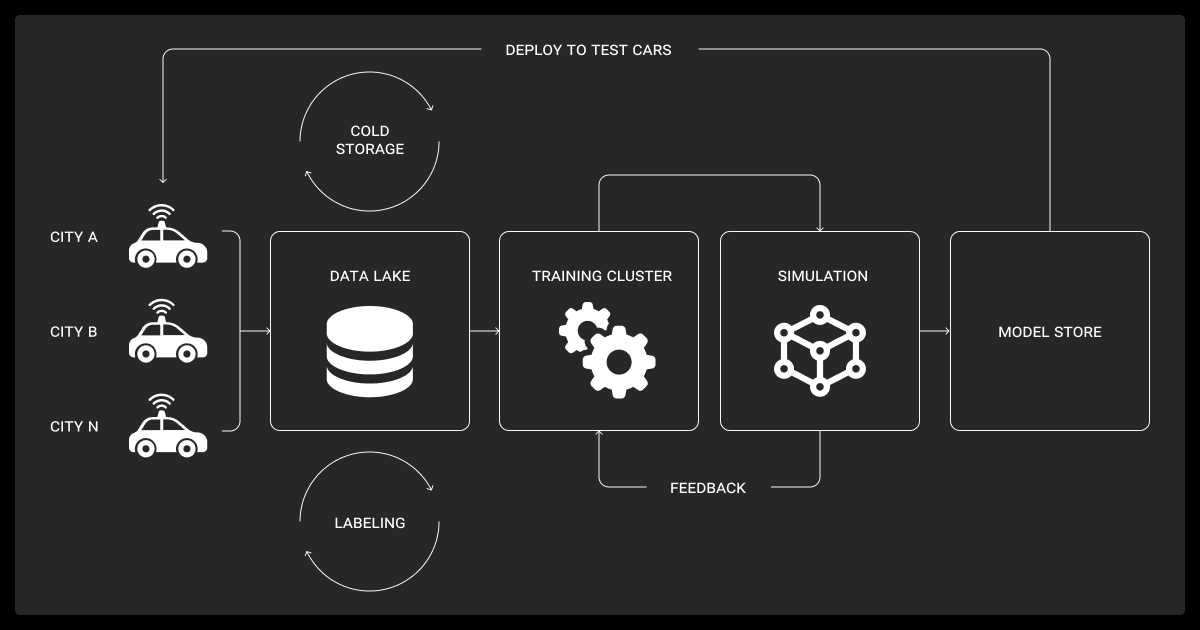
High-Volume, High-Frequency, Multimodal Inputs
Autonomous vehicles don’t rely on just one sensor, they use a whole mix:
- Cameras (RGB, stereo, fisheye): 30–60 FPS
- LiDAR: 10–20 Hz, with thousands of 3D points per frame
- Radar: 1–20 Hz, strong on velocity and range
- IMU/GPS: Continuous localization and pose
Just one test run can generate terabytes of data, especially when you’re recording everything in sync. To make any of the data collected by autonomous vehicles usable, you need tight synchronization, usually down to 10 milliseconds or better, so everything lines up for fusion and time-series modeling.
Modern fleet telematics systems play a key role in achieving that level of precision, ensuring each sensor’s data is timestamped, synced, and transmitted reliably during test runs.
Environmental Factors and Sensor Noise
Even top-tier hardware can’t beat Mother Nature. Here are some things that can cause problems:
- Sudden lighting shifts can wash out or darken video feeds.
- Rain, fog, or snow eat into LiDAR and camera quality.
- Reflective surfaces can trick sensors with phantom objects.
Ironically, these are the scenarios we most want AVs to master, because they represent dangerous conditions in the wild. But they also make data collection and data annotation a lot more complicated.
In-the-Wild Data Quality Failures
We can hope for clean, well-behaved data, but this is rare to come across. You’re likely to encounter dropped frames, I/O slowdowns, and packet loss during data collection for autonomous vehicles.
A single pothole can throw your LiDAR–camera alignment off. Metadata errors like GPS drift and misaligned timestamps can snowball into broken perception pipelines. This is why you have to be so careful with techniques like GIS data collection, and why working with experienced teams can save you from costly rework.
Catching these issues early with automated Quality Assurance (QA) helps avoid costly rework and keeps model performance from tanking.
One lesson I learned early on is the importance of balancing data volume with quality — collecting too much raw data can overwhelm storage and processing, so filtering at the sensor level is critical.

 Co-Founder & CEO, AIScreen
Co-Founder & CEO, AIScreen
The Sensor Stack Behind Autonomous Vehicle Data Collection
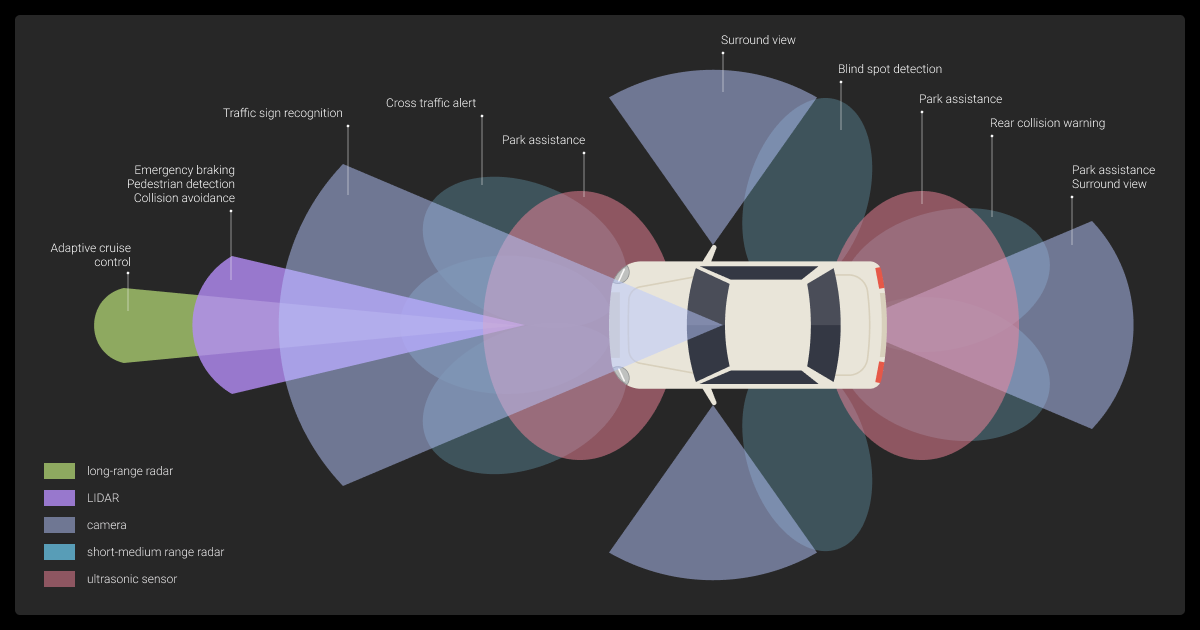
First, you need to understand how autonomous vehicles collect data. AVs navigate by stacking sensors on top of each other, each of which views the world differently. Together, all these sensors create a full picture.
Sensor Modalities and What They Capture
| Sensor | What It Measures | Strengths | Weaknesses |
| Cameras | Color, texture, semantics | High-res, low-cost | Bad depth, light-sensitive |
| LiDAR | 3D structure, object contours | Accurate, night-capable | Expensive, weak in weather |
| Radar | Distance and velocity | Motion tracking, weather-resistant | Low-res, noisy |
| IMU/GPS | Pose, acceleration, heading | Essential for localization | Drift, GPS dropouts |
Every sensor has blind spots, which is why we combine them. We might also include other sensors based on the secondary uses of the data collected by autonomous vehicles.
Fusion Complexity and Failure Modes
Sensor fusion isn’t just layering data on top of data. It’s a careful process of aligning time, syncing coordinates, and resolving conflicting inputs. The downside is that it’s not always obvious when it breaks. You might see objects misaligned across modalities, time lags, or blank spots where a sensor dropped out.
Probabilistic models like occupancy grids or Monte Carlo localization can help smooth over the rough edges, but they’re not flawless.
Calibration and Mounting Considerations
Mount something even slightly off, and the whole stack can fall apart. You’ve got two types of calibration to worry about:
- Intrinsic: Within a sensor, for example lens distortion
- Extrinsic: Between sensors, for example LiDAR to camera alignment
A tiny mounting angle, just one or two degrees off, can skew your depth readings or object boundaries. Your mounts need to be rock-solid and easy to recalibrate in the field when things inevitably shift.
Without proper planning for these kinds of issues, your automated data collection can fall short.
Multimodal sensors are the first step in the perfect configuration. RGB and depth cameras, LiDAR for spatial awareness, and an IMU for motion tracking are all necessary. Early standardization is crucial — your model training pipeline will become a transformation bottleneck if each team logs data in a different way.
 Head of Data and AI, Creative Fabrica
Head of Data and AI, Creative Fabrica
Data Formats in Autonomous Vehicle Pipelines
Raw data isn’t useful until you structure it properly. Different teams use different formats depending on their goals, training, annotation, simulation, debugging.
ROS, PCAP, and Other Native Logging Formats
Each format comes with tradeoffs:
- ROS bags: These are great for prototyping and academic work.
- PCAP: This captures raw network packets, often used for radar/LiDAR.
- Proprietary formats: These give better compression and rich metadata support.
No matter what format you use, file size, metadata quality, and compatibility with downstream tools are ongoing headaches.
ML Constraints: Alignment, Resolution, and Precision
You usually need to preprocess all data before creating your machine learning dataset. This means:
- Aligning modalities
- Cropping or downsampling
- Converting from high-precision floats to int8 or lower
If you don’t align the data just right, you end up with bad labels, confused models, and bloated error rates.
Tools for AV Data Collection and Synchronization
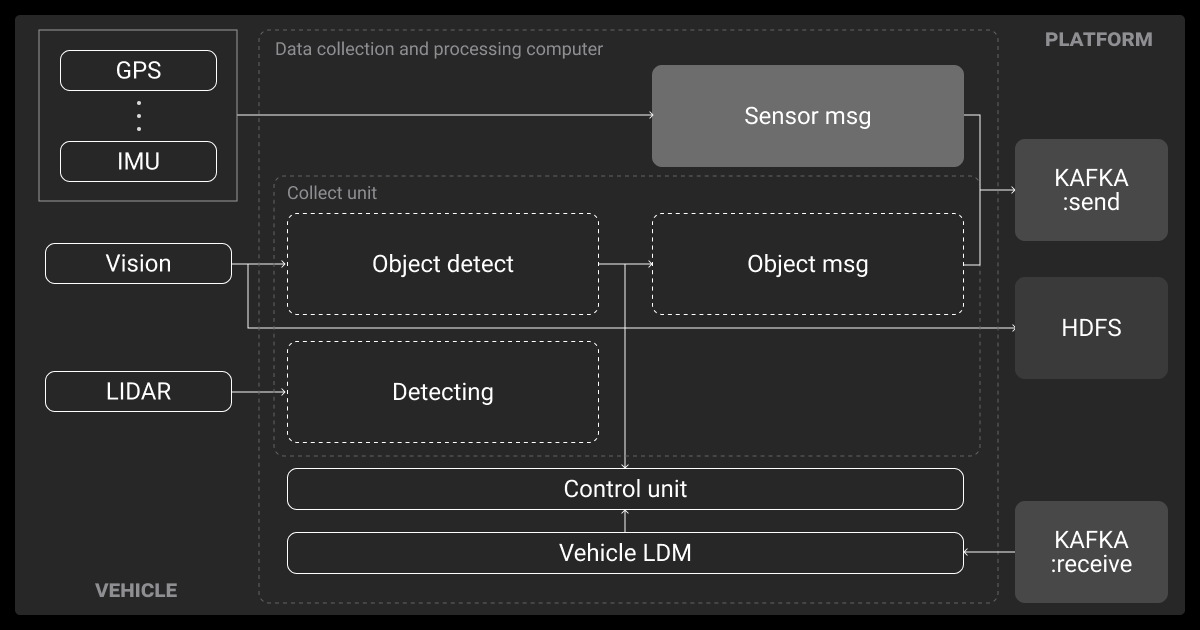
The AV data pipeline runs from the vehicle to the cloud, with a lot of complexity in between. If you partner with video annotation services or a data annotation company, they’ll usually have a range of tools that simplify the pipeline.
Onboard Loggers and Edge Gateways
Self-driving cars are basically rolling data centers. Inside, you’ll find:
- SSDs writing at 10+ Gbps
- Edge gateways tagging data with GPS, weather, and in-cabin events
Field teams use dashboards and lightweight labeling tools to tag key moments, like “dense traffic” or “driver takeover at 32:12,” while they’re still fresh. Capturing this context accurately is essential for downstream model training and review.
Upload Pipelines, Metadata Capture, QA Layers
Once the car’s back, you need to offload the data. That could mean using a depot Wi-Fi, cellular sync, or even physically swapping hard drives. Your upload systems should run automated checks for:
- Missing frames
- Corrupted log
- Metadata integrity
Early quality assurance tools filter out broken calibration or missing GPS and other broken survey data collection so it doesn’t clog the training queue later.
Cloud Storage, Versioning, and Budget Constraints
At fleet scale, data isn’t just big, it’s expensive. A fleet can rack up over 100 TB of data per day, even with basic image recognition tools. That means making some trade-offs in:
- Cloud egress costs
- Cold storage policies
- And making sure the indexing compute all adds up
Teams lean on deduplication, versioning, and usage tracking to decide which clips are worth keeping and which to discard. It’s better to work with a smaller, highly relevant dataset than one cluttered with errors or broken data.
LiDAR sensors paired with high-res cameras give us the most reliable data, though managing the massive files was tricky at first. We ended up using AWS S3 for storage and Apache Kafka for real-time streaming.
 CEO, Magic Hour
CEO, Magic Hour
Inside the Autonomous Vehicle Data Collection Workflow
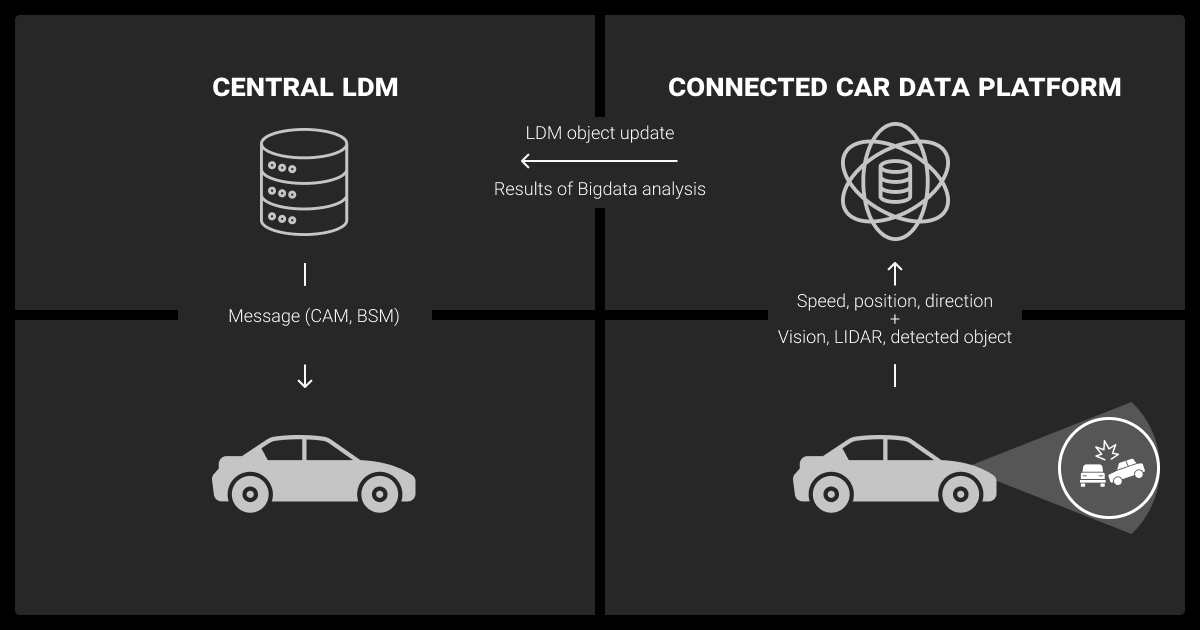
Once a vehicle rolls out, the pipeline kicks into gear automatically.
Preprocessing Requirements for Perception Tasks
Your first step is to clean it up. That usually means:
- Syncing timestamps using GPS/IMU
- Reprojecting LiDAR into camera frames
- Dropping bad footage (fog, debris, blocked lenses)
Using the right data collection tools and data collection methods can make this easier. Data annotation for autonomous vehicles can also go faster if you use autotags like “pedestrian” or “weird maneuver.” These essentially flag interesting moments for your team to triage later.
Labeling Strategy: Model-in-the-Loop and Manual QA
Annotation is a hybrid job. First, pretrained models tag everything they can, including complex tasks like LiDAR annotation. Then human QA teams refine and validate. In tough cases, active learning flags uncertain frames so experts can weigh in.
Labeling short clips keeps the context tight and reduces drift. You just have to ensure consistency across the whole process.
Throughput Benchmarks for Annotation Teams
| Task | Time per Frame | Notes |
| 2D Bounding Boxes | 5–10 sec | Faster with model-in-loop |
| 3D Cuboids (LiDAR) | 30–60 sec | Calibration-dependent |
| Semantic Segmentation | 2–5 min | Slowest, especially high-res |
| QA/Validation | 3–10 sec | Smart sampling speeds things up |
Even a few seconds here and there can add up to thousands of hours at fleet scale.
Security and Compliance in Autonomous Vehicle Data Collection
Driverless vehicles don’t just record the road, they record people. That means privacy isn’t optional; it has to start from day one.
Capturing PII, Biometric Data, or Driver Behaviors
Sensitive data shows up fast:
- Faces and license plates
- In-cabin driver behavior
- Audio that might capture speech
The solution starts with anonymization; blur it, mask it, or strip it. Then you lock access down with strict controls and role-based permissions.
Regulatory Constraints by Region (GDPR, CPRA, BIPA)
Where you collect matters.
| Regulation | Region | Key Requirements |
| GDPR | EU | Consent, data deletion, access rights |
| CPRA | California | Opt-outs, transparency |
| BIPA | Illinois (US) | Explicit consent for biometrics |
Global fleets often isolate data by geography to avoid compliance nightmares.
Scaling Up Your AV Data Collection Without Burning Out Your Team
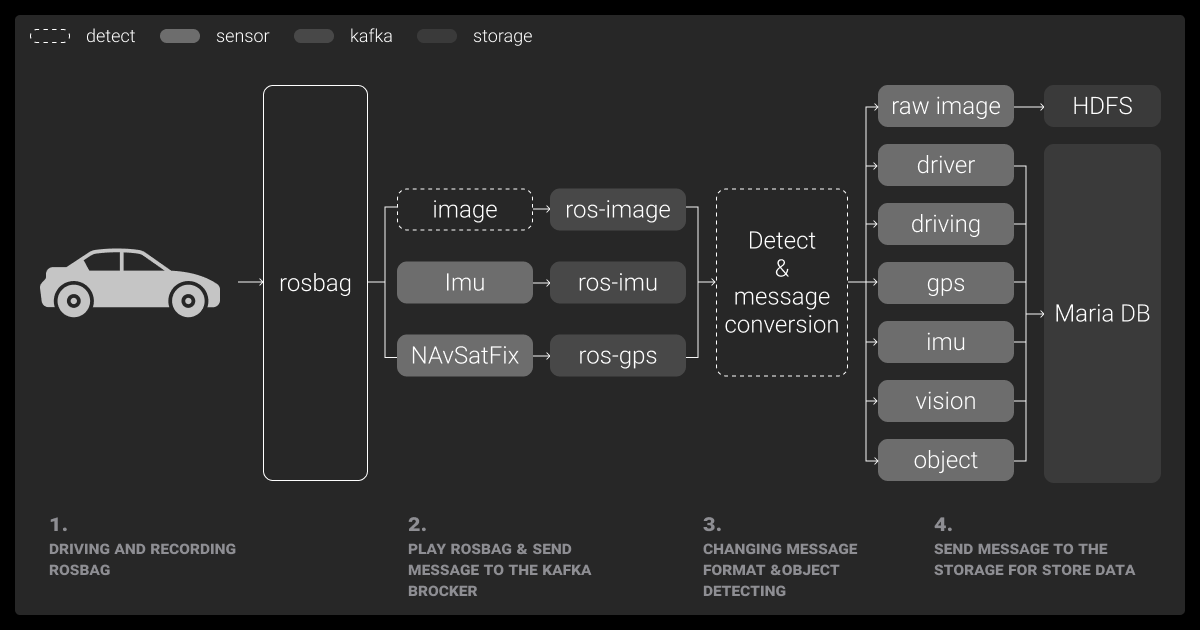
Eventually, in-house teams hit a wall. Outsourcing to reputable data annotation services and data collection services helps when you need to scale fast or gather data in unfamiliar regions.
When In-House Breaks Down (Cost, Scale, Expertise)
Outsourcing makes sense when:
- Your internal team can’t keep up with labeling
- QA needs grow too quickly
- You need local data from another country
- Your internal data annotation pricing is getting too expensive
You’ll trade off control for flexibility, but the right partner can close that gap.
What to Look for in a Vendor (Tooling, QA, Security)
The best vendors don’t just throw people at the problem. They offer:
- Support for complex tasks like 3D labels and sensor fusion
- Multi-pass QA with real model feedback
- Enterprise-grade security: SOC 2, ISO 27001, GDPR
Bonus: If they plug directly into your existing tools and APIs, onboarding becomes a breeze.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is vehicle data collection?
It’s the process of capturing sensor streams, metadata, and driver behavior during real-world drives. That data teaches AV models how to perceive, predict, and plan safely.
How do autonomous vehicles collect data?
Autonomous vehicles (AVs) use synced sensors (cameras, LiDAR, radar, GPS, IMU) to log multimodal data during every drive. Onboard tools tag metadata in real time, and cloud pipelines handle validation and storage.
What is the best dataset for autonomous vehicles?
Public sets like Waymo Open, nuScenes, Argoverse, and KITTI are great for benchmarks. But most AV companies use proprietary data tailored to their tech and location.
How does Waymo collect data?
Waymo cars use high-res cameras, full-circle LiDAR, and radar. Data gets logged onboard, uploaded to the cloud, then processed for anonymization, labeling, and training.
What data might be collected by the car’s sensors?
Autonomous vehicles collect multimodal data including images, 3D point clouds, radar reflections, GPS coordinates, IMU readings, and audio. This can capture objects, lane markings, motion, location, acceleration, and driver or passenger activity, often with precise timestamps for sensor fusion.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.