RAG Evaluation: Metrics and Benchmarks for Enterprise AI Systems

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- Enterprise RAG evaluation prioritizes factual grounding, retrieval quality, and compliance risks alongside accuracy.
- Retrieval metrics: precision@k, recall@k, MRR, nDCG. Generation: faithfulness, relevance, citation coverage, hallucination rate. End-to-end: correctness, factuality, latency, cost, safety.
- Test sets combine golden data, synthetic queries (Ragas, ARES), and human review. Freezing versions keeps results comparable.
- Benchmarks include RAGBench, CRAG, LegalBench-RAG, WixQA, T²-RAGBench. Tools like Ragas, ARES, LangSmith, AWS Bedrock, Vertex AI support applied evaluations.
- In production, evaluation must be continuous through batch or online A/B tests, monitoring dashboards, and governance; this way balancing accuracy, cost, latency, and multilingual needs.
Enterprise Priorities When Evaluating RAG Systems
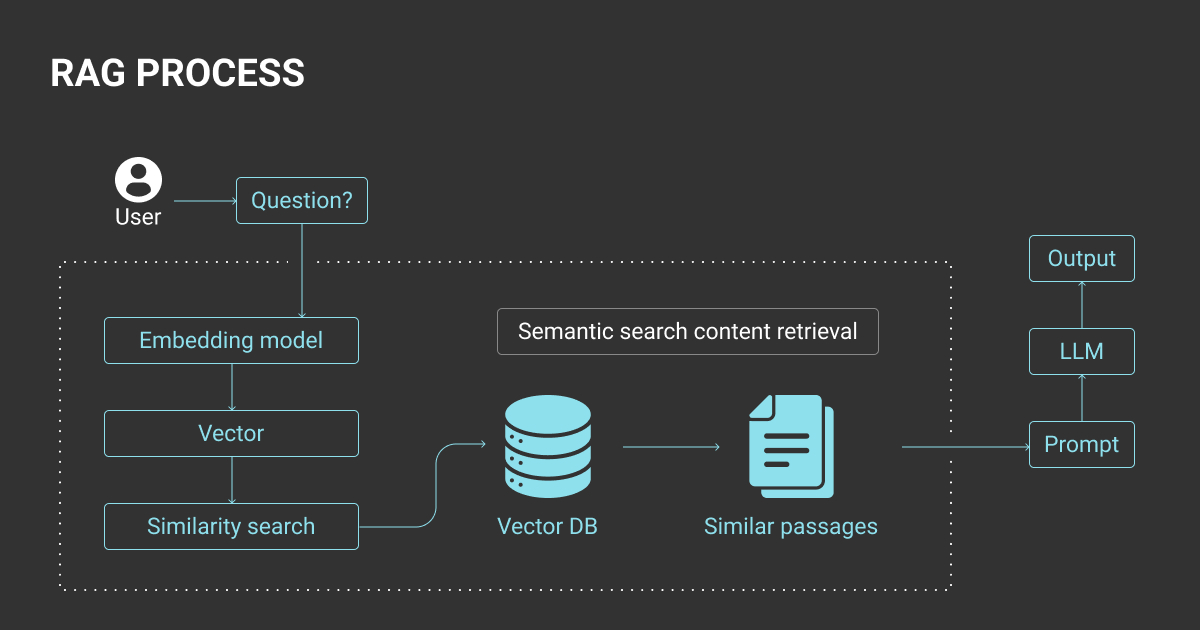
Evaluation of Retrieval-Augmented Generation, or RAG LLM systems needs more than simple accuracy checks. For enterprises, errors in retrieval or generation can mean compliance failures, reputational damage, or even legal exposure. That’s why factual accuracy and grounding must come first, with retrieval relevancy close behind.
A RAG evaluation framework starts with understanding the distinct roles of its two components:
- Retrieval: pulls relevant documents from knowledge bases
- Generation: synthesizes responses using that context
Evaluations must measure both and also assess the end-to-end experience. Simple sandbox testing falls short because a perfect retriever paired with a hallucination generator, or vice versa, still produces unusable outputs.
For ML teams, the core question isn’t “does it work in tests?” but “will it hold up reliably at scale, under regulatory and customer scrutiny?” Enterprise-grade RAG evaluation means treating factual grounding, retrieval quality, and end-to-end correctness as operational KPIs, not optional checks.
Key RAG Evaluation Metrics Across the Pipeline
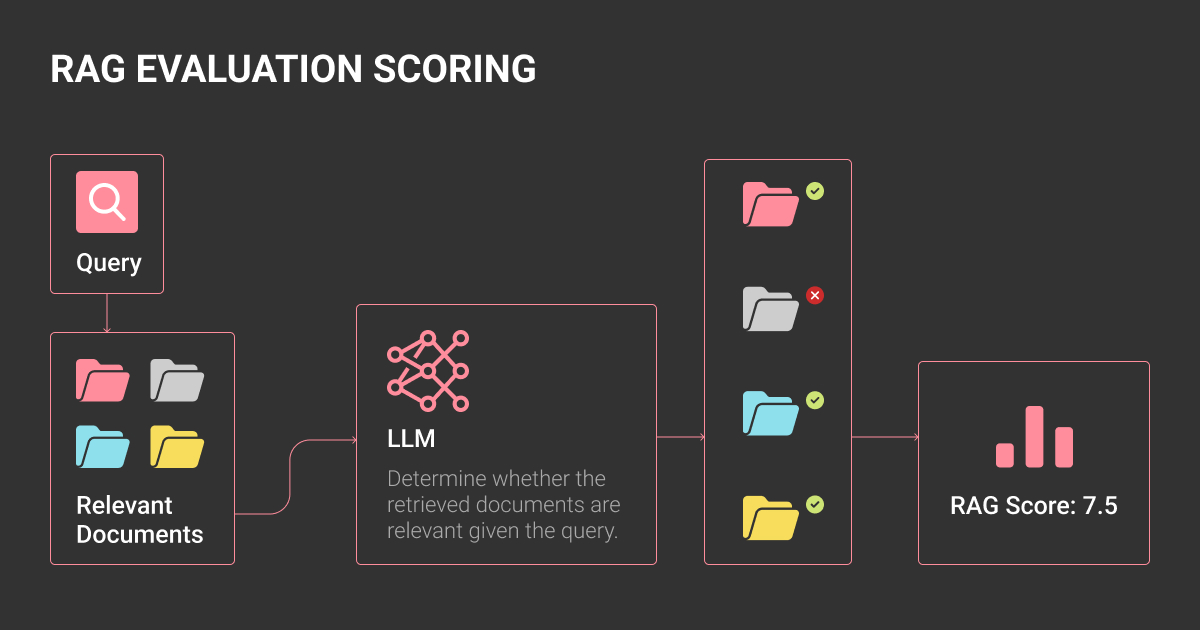
Measuring RAG performance requires tracking three layers: retrieval, generation, and the combined end-to-end pipeline. Computation-based scores (string match, embeddings) are reproducible but limited; LLM-as-a-judge methods capture nuance but add cost and variability. Most ML teams blend both approaches.
Retrieval
Core retrieval metrics include precision@k (are the top-k documents relevant?), recall@k (how much of the relevant info was retrieved?), Mean Reciprocal Rank (MRR) (are correct docs ranked early?), and Normalized Discounted Cumulative Gain (nDCG) (graded relevance with position weighting). For enterprises, it’s often useful to add diversity metrics so the retriever doesn’t repeatedly surface narrow or redundant content.
Generation
At the generation stage, the focus shifts to faithfulness (is output grounded in retrieved docs?), answer relevance (does it address the query?), citation coverage (are claims backed with sources?), and hallucination rate (unsupported or fabricated text). Some enterprise frameworks also add logical coherence and completeness as dimensions of answer quality.
End-to-End
Finally, evaluate the pipeline as users experience it: correctness vs factuality, latency and cost under load, and safety/compliance (refusal rates, harmful content, or policy violations). End-to-end evaluation highlights real trade-offs (e.g., raising k improves recall but increases latency and spend).
Companies often judge RAG systems by answer quality alone, but ignore cost and latency. A demo may look impressive, yet in production repeated lookups and large LLM calls can drive costs up and frustrate users. Evaluation must cover accuracy, relevance, latency, and cost together.

 AI Engineer, Vention
AI Engineer, Vention
Building Reliable Test Sets for RAG Evaluation
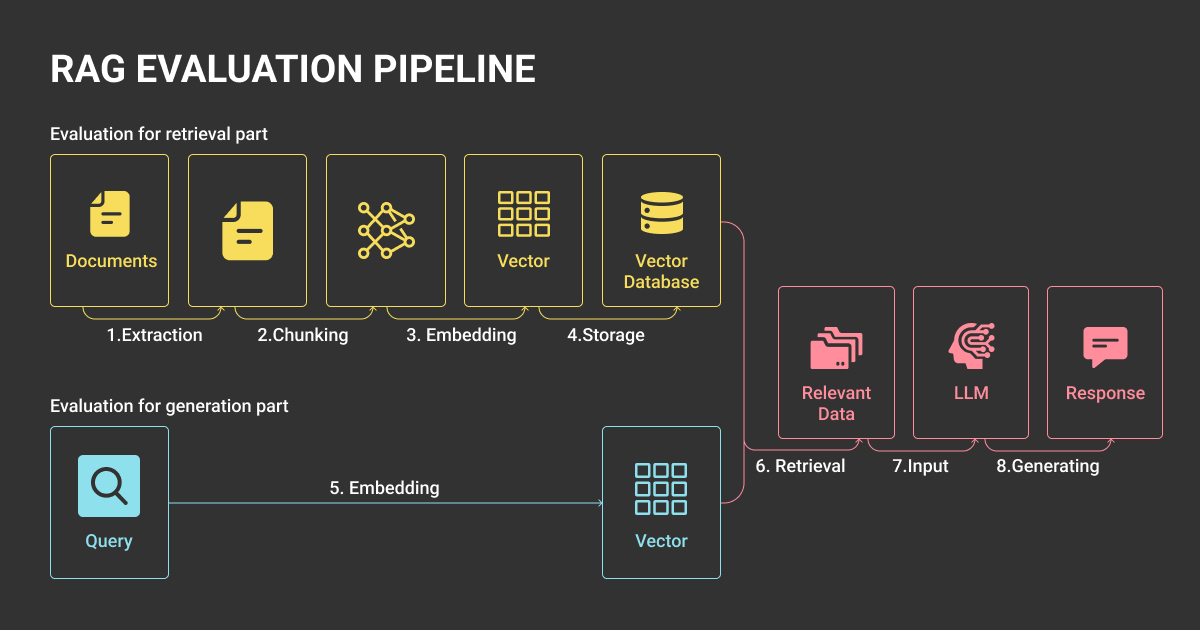
Strong evaluation depends on strong test sets. You can’t rely on ad-hoc samples or live traffic; they need carefully designed datasets that are auditable and reproducible.
Golden datasets remain the foundation. These should cover the full scope of the system, balance easy and hard queries, and include governance rules for updating without breaking comparability. Freezing golden sets for each evaluation cycle is critical. Otherwise, RAG evaluation metrics lose meaning across time.
For teams evaluating systems against rapidly changing information, web scraping or an alternative scraping service can help continuously collect fresh content from external sources, ensuring test datasets reflect the same dynamic environments that production RAG systems must handle.
Golden datasets serve a role similar to curated projects at a data annotation company: balanced, documented, and reproducible so results hold up under audit.
Synthetic datasets help scale coverage where golden data is limited. Tools like Ragas and ARES benchmark RAG evaluation can automatically generate synthetic queries and answers, or stress-test retrieval pipelines with adversarial examples. The research notes that synthetic data is valuable, but enterprises must validate with human review to prevent models from learning synthetic artifacts.
Human-in-the-loop checks remain non-negotiable for edge cases. Annotators can flag ambiguous, multi-intent, or safety-critical queries that automated tools struggle with. Teams that skip human review often miss systemic issues in compliance-heavy use cases, such as finance or healthcare.
In practice, reliable test sets balance golden, synthetic, and human-reviewed data, with strict versioning to guarantee comparability across evaluation runs. For enterprises, it’s how you build trust in RAG systems across teams and audits.
Benchmarks and Tools for Evaluating RAG

Benchmarks and tools for RAG evaluation are expanding fast, but enterprises need clarity on which to trust and when to use them. Academic benchmarks test general capabilities, while frameworks and cloud tools focus on applied monitoring and evaluation.
Benchmarks
Benchmarks provide a common yardstick for comparing RAG systems across machine learning datasets, domains, and types of LLMs. They go beyond basic accuracy checks by testing how well retrieval and generation interact under controlled conditions.
- RAGBench: General-purpose retrieval + generation benchmark, widely used in academic research
- CRAG: Emphasizes contextual relevance and grounding, useful for retrieval-heavy domains
- LegalBench-RAG: Tailored to legal QA tasks, where hallucination or mis-citation has compliance impact
- WixQA: Web-scale QA benchmark, designed to measure factual grounding across heterogeneous sources
- T²-RAGBench: Focuses on multi-turn and task-oriented RAG evaluation
For enterprises, these evaluations complement internal data annotation efforts by showing how models perform on standardized tasks. The choice of benchmark matters: a legal QA benchmark highlights compliance risks, while a web-scale QA set stresses grounding and recall at scale.
RAG Evaluation Frameworks and Tools
Enterprises have more options than ever for measuring RAG performance. Evaluation frameworks and cloud tools now combine LLM evaluation methods, synthetic dataset generation, and monitoring features.
- Ragas: Open-source framework for evaluating retrieval and generation, with built-in synthetic data generation
- ARES: Stress-tests retrieval systems with adversarial examples
- LangSmith: Provides LLM-as-a-judge evaluators and retrieval metrics, plus experiment tracking
- AWS Bedrock eval: Adds enterprise-ready metrics like citation precision and logical coherence, integrated into managed workflows
- Vertex AI eval (Google Cloud): Combines human evaluation with model- and computation-based metrics in a structured framework
Synthetic data generation can help control costs in evaluation, much like careful scoping influences data annotation pricing in traditional ML workflows.
Some build on ideas from data annotation services, while others extend into advanced areas such as agentic RAG and pipeline observability. The right choice depends on whether your team is comparing models, stress-testing a machine learning algorithm, or monitoring live systems in production.
The takeaway for enterprises: benchmarks are useful baselines, but tools are what keep systems safe in production.
Benchmark scores can highlight broad limitations, but governance and monitoring rely on RAG evaluation frameworks that support continuous evaluation, reproducibility, and integration with enterprise pipelines.
One of the biggest mistakes in RAG evaluation is focusing too much on technical benchmarks and not enough on real business performance. Even a strong model will fail if the knowledge base is inconsistent or poorly structured. Cleaning and organizing source data made our implementations far more reliable.
 CEO, Bookyourdata
CEO, Bookyourdata
Operationalizing RAG Evaluation in Production
Running one-off tests is not enough for enterprises. RAG systems must be evaluated continuously, with monitoring that captures both technical metrics and business impact.
From lab to production. Lab experiments validate feasibility, but production demands ongoing checks. For teams that lack dedicated ML infrastructure or in-house RAG expertise, this operational burden is often where projects stall. Working with a RAG as a service partner can address this directly: handling platform selection, data pipeline setup, and ongoing optimization so enterprises can move from evaluation to production faster and without building the full stack in-house.
Enterprises move from batch evaluations on frozen datasets to online A/B testing that compares new retrieval or generation strategies against established baselines.
Observability and governance. Enterprises need dashboards that track retrieval precision, LLM hallucination rate, latency, and cost in real time. Governance frameworks – similar to model cards or data audits – ensure results are documented, reproducible, and explainable across teams and regulators.
Trade-offs at scale. Raising k improves recall but slows response time and raises compute cost. Adding re-rankers boosts precision but can multiply latency. Multilingual pipelines add another layer of complexity: a system may perform well in English but degrade in other languages if test sets aren’t balanced. Enterprises must track these trade-offs explicitly, aligning them with SLAs and risk tolerances.
The enterprise mindset. Operationalizing RAG evaluation means treating it as part of production governance, not just ML experimentation. The goal is predictable, compliant, and cost-effective performance across the lifecycle of the system.
Enterprises often weigh RAG vs fine tuning when moving systems into production. Fine-tuned models can excel on fixed datasets, while RAG pipelines adapt to new knowledge but demand continuous monitoring and evaluation.
About Label Your Data
If you choose to delegate LLM fine-tuning, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is a RAG evaluation?
A RAG evaluation is the process of measuring how well a Retrieval-Augmented Generation (RAG) system performs. It assesses the retriever (are the right documents surfaced?), the generator (are answers faithful, relevant, and grounded?), and the end-to-end pipeline (is it correct, safe, and efficient). Enterprises use RAG evaluation to monitor accuracy, compliance, latency, and cost.
Is ChatGPT a RAG model?
No. ChatGPT in its base form is a large language model (LLM) without retrieval. A RAG model combines an LLM with an external knowledge retriever, so it can ground answers in up-to-date or domain-specific data. Some ChatGPT features, like browsing or custom knowledge base connections, add retrieval components and make it behave more like RAG.
What is the difference between RAG and LLM?
An LLM generates answers based only on patterns learned during training. A RAG system pairs an LLM with a retriever that fetches relevant documents at query time. This reduces hallucinations, keeps outputs current, and makes it possible to adapt models to enterprise data without retraining.
What is the purpose of a RAG?
The purpose of a RAG system is to improve reliability and accuracy by grounding model outputs in external sources. For enterprises, this means lower hallucination risk, better compliance, and the ability to update answers dynamically as knowledge changes.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.