3D LiDAR: Point Cloud Annotation and Mapping Technology Explained

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- When 3D LiDAR Datasets Become Your ML Pipeline Bottleneck
- What Is 3D LiDAR and Why ML Engineers Should Care
- How 3D LiDAR Works: From Laser Pulse to Point Cloud
- 3D LiDAR Point Cloud Data Structures ML Pipelines Must Handle
- When 3D LiDAR Becomes Critical and What It Demands from Your Model
- Why 3D LiDAR Annotation Takes 6-10x Longer
- 3D LiDAR Annotation Tools and Build vs Buy Decisions
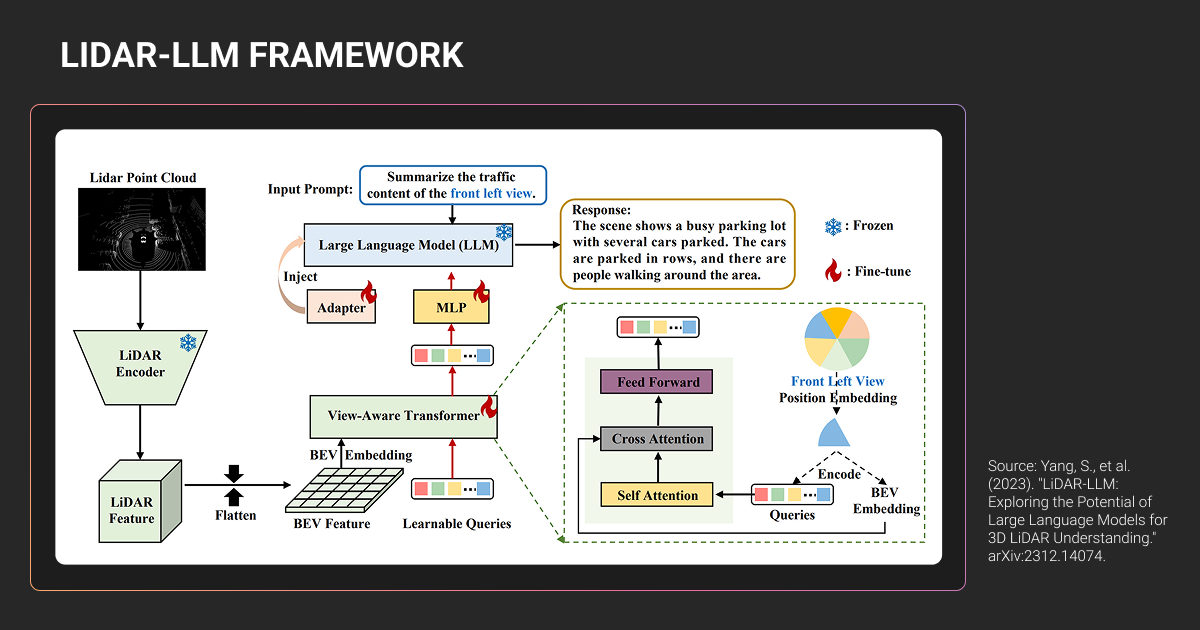
- 4D LiDAR: An Emerging Capability Worth Monitoring
- About Label Your Data
- FAQ

TL;DR
- 3D LiDAR generates point clouds: unordered sets requiring different model architectures (PointNet, VoxelNet, PointPillars) than image CNNs, with annotation format tied directly to your model choice.
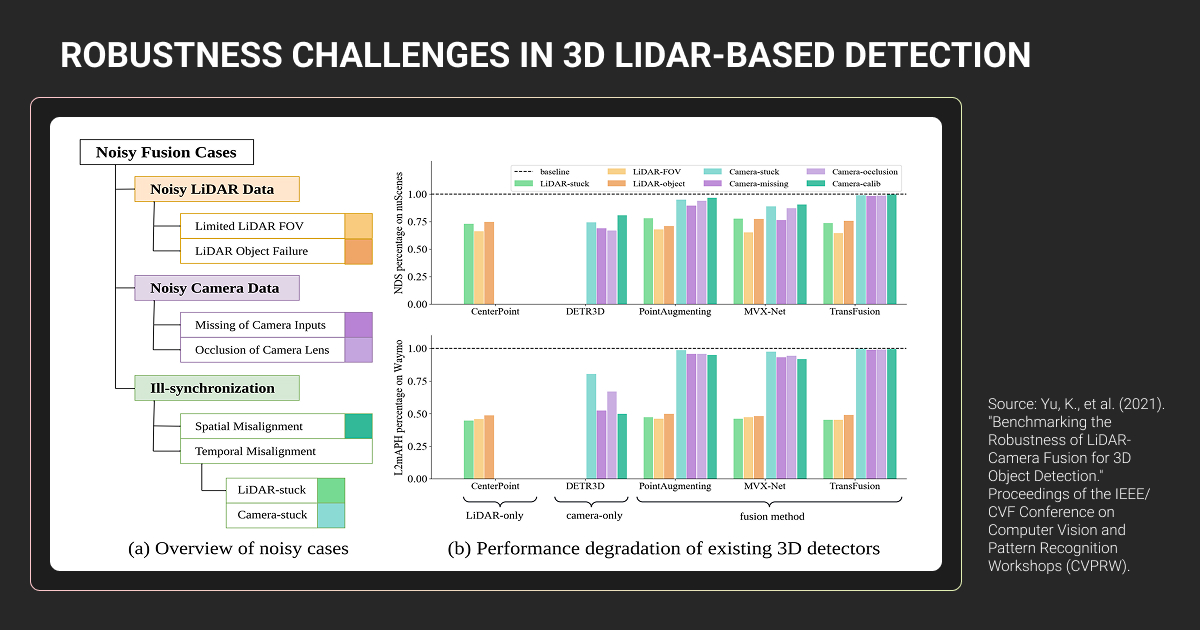
- Sensor fusion (LiDAR + cameras) provides the redundancy most autonomous systems need, but point cloud annotation takes 6-10× longer due to 3D spatial complexity and sparse data at distance.
- Model architecture, annotation quality, and build vs buy decisions compound through your pipeline; misalignment at any stage means rebuilding datasets or retraining teams.
When 3D LiDAR Datasets Become Your ML Pipeline Bottleneck
Your autonomous vehicle model keeps missing objects in 3D space.
Public datasets like KITTI or nuScenes don’t match your sensor configuration. Your 3D LiDAR annotation pipeline is taking 6-10x longer than image labeling, and you’re not sure if the quality justifies the cost.
You might find yourself asking:
- Do we actually need LiDAR, or can vision-only work?
- If we commit to 3D point clouds, what does that mean for our training data pipeline?
- How do we evaluate if our annotation quality is the bottleneck?
For ML engineers building autonomous systems, 3D LiDAR is a fundamentally different data structure that requires rethinking how you collect, annotate, and validate training data.
What Is 3D LiDAR and Why ML Engineers Should Care
3D LiDAR is a sensing technology that maps physical environments using laser light. It fires rapid laser pulses, measures how long they take to return, and calculates the distance to every surface they hit.
The result is a point cloud: millions of x, y, z coordinates representing 3D space.
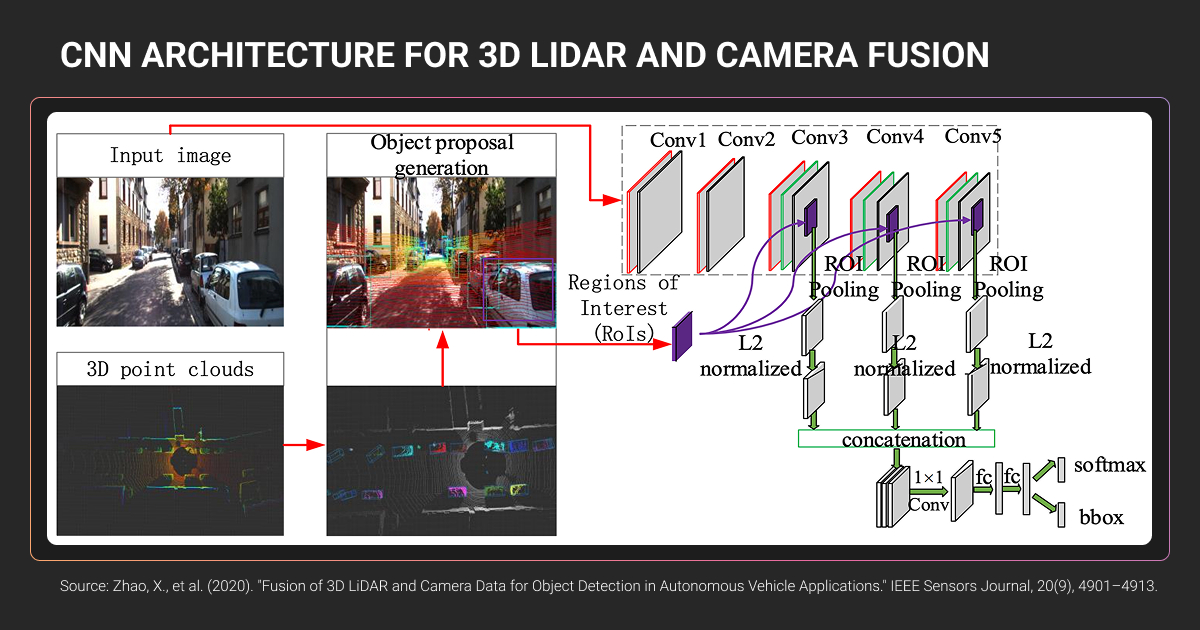
If you’re building perception models for autonomous vehicles, robotics, or drones, these point clouds are your training data. Unlike camera images that require depth estimation, LiDAR gives you direct 3D measurements of every object in the scene.
Point clouds are unordered sets: there’s no pixel grid, no fixed structure. Standard CNNs can’t process them directly. This means different model architectures (PointNet, VoxelNet, PointPillars) and different LiDAR 3D annotation requirements than 2D images.
Camera-only models struggle with depth precision and occlusion.
LiDAR point clouds give you exact 3D spatial relationships, but raw unlabeled data needs annotation before it trains anything. Annotation quality directly impacts model accuracy, given that annotation errors can degrade performance by over 25%.
How 3D LiDAR Works: From Laser Pulse to Point Cloud
A LiDAR 3D scanner operates through time-of-flight measurement.
LiDAR sensors emit laser pulses and measure return time to calculate distance. Achieving centimeter-level accuracy requires extremely precise timing.
Modern automotive 3D LiDAR sensors use two wavelengths. The 905nm wavelength (Velodyne, Ouster, Livox) is mature and cost-effective but power-limited for eye safety. The 1550nm wavelength (Luminar) allows significantly higher pulse energy while remaining eye-safe, enabling better weather performance and longer range.
Three scanning mechanisms produce different point cloud characteristics:
- Mechanical rotating LiDAR spins the entire assembly 360° with multiple stacked laser channels, producing uniform coverage with consistent point spacing
- MEMS-based LiDAR uses vibrating mirrors with limited rotation angles, requiring multiple sensors for surround coverage and creating irregular point distributions
- Solid-state LiDAR uses rotating prisms with non-repetitive patterns, achieving higher density over time but with variable point distribution across frames
Each laser pulse records distance, angle, and return intensity. Combined with GPS/IMU data, these transform into x, y, z coordinates.
Point density varies dramatically with distance. At 2 meters, you might see ~1,000 points per square meter, dropping to ~10 points per square meter at 20 meters.
This matters for data annotation work. A pedestrian at 20 meters appears as hundreds of points; at 50 meters, only a few dozen remain. Your annotators are making judgment calls on sparse data, which is why 3D bounding box placement becomes significantly harder at distance.
For a visual demonstration of how rotating 3D LiDAR sensors scan environments in real-time, this visualization shows the scanning process clearly.
3D LiDAR Point Cloud Data Structures ML Pipelines Must Handle
A 3D LiDAR point cloud is an unordered set of 3D coordinates with optional attributes.
Each point contains x, y, z positions (typically in meters), intensity (8 or 16-bit return signal strength), return number (for multi-return systems), and optional RGB color from camera fusion.
Your data pipeline will encounter four primary file formats:
| Format | Primary use case | Structure | Typical size |
| BIN | Autonomous driving (KITTI, nuScenes) | Raw float32 arrays (x, y, z, intensity), no header | 1.6-2 MB per frame |
| PCD | Robotics (ROS-based systems) | ASCII headers, binary/compressed data, memory-mapped I/O | Variable with compression |
| LAS/LAZ | Aerial and geospatial mapping | ASPRS standard with georeferencing, 4:1-7:1 compression | Large datasets |
| PLY | Computer graphics, reconstruction | Cross-platform, supports points and mesh data | Varies by content |
Point density drops dramatically with distance: ~1,000 points/m² at 2 meters versus ~10 points/m² at 20 meters.
Your model must detect objects from vastly different point counts. A car at 50 meters might have only a few dozen points defining its shape. GPU memory constraints limit batch sizes during training, which directly impacts iteration cycles.
When 3D LiDAR Becomes Critical and What It Demands from Your Model
The 2D LiDAR vs 3D LiDAR decision matters for model capabilities.
2D LiDAR scans a single horizontal plane — adequate for AGVs on flat warehouse floors. 3D LiDAR captures volumetric data essential for detecting pedestrians, cyclists, overhanging objects, and varying terrain.
Critical use case scenarios
3D LiDAR becomes essential in specific contexts:
- Safety-critical autonomy (Level 3+): Mercedes-Benz and BMW achieved Level 3 certification using LiDAR-based systems; production robotaxis demonstrate significantly lower disengagement rates than vision-only approaches
- Adverse conditions: LiDAR maintains centimeter accuracy in complete darkness; heavy rainfall reduces detection distance substantially, though it still outperforms cameras in low-visibility scenarios
- Precision industrial applications: Autonomous forklifts, mining equipment, and infrastructure inspection require sub-centimeter accuracy; LiDAR 3D mapping enables surveying and terrain analysis at scale
Vision-only approaches remain viable for ADAS features at Levels 1-2, controlled environments, and cost-sensitive mass-market vehicles.
The autonomous vehicle industry has largely settled this debate.
The majority of new AV platforms incorporate 3D LiDAR sensors as standard equipment. Tesla remains the notable exception with camera-only FSD, though they've reportedly purchased LiDAR sensors for testing. The technical consensus: sensor fusion provides redundancy that camera-only systems lack.
The robotics community actively debates these tradeoffs. This Reddit discussion covers real-world experiences with different LiDAR configurations for various applications.
Model architecture requirements
Standard CNNs cannot process point clouds because the data structure is fundamentally incompatible. Point clouds are unordered sets with variable density, and most voxel space is empty when converted to 3D grids.
Three architecture families dominate:
- PointNet/PointNet++: Treats point clouds as sets, uses shared MLPs for per-point features, applies max pooling for permutation invariance
- VoxelNet: Converts points into 3D voxel grids, applies 3D CNNs (computationally expensive with slower inference)
- PointPillars: Groups points into vertical columns, applies 2D convolutions only (significantly faster real-time performance)
For implementation details on these architectures, see our 3D object detection guide.
Your choice determines LiDAR 3D annotation requirements. Detection models need oriented 3D bounding boxes with 7 degrees of freedom. Segmentation models require per-point semantic labels.
If you annotate only 3D boxes but later switch to segmentation, your dataset lacks per-point labels. Model architecture and annotation strategy must align upfront.
Ouster, a LiDAR sensor manufacturer, faced exactly this challenge when scaling their ML pipeline. Their annotation needs spanned static and dynamic sensors across varied environments: interior, exterior, different lighting conditions.
Ouster needed to scale their annotation capacity while maintaining quality standards across diverse machine learning datasets. Working with Label Your Data, they grew to 10 annotators trained specifically on LiDAR data characteristics.
We delivered both 2D bounding boxes and 3D cuboids, handling the sparse data and occlusion patterns inherent to point clouds. The partnership resulted in 20% product performance gains, 0.95 F1 score, and 15% improved tracking accuracy.
Why 3D LiDAR Annotation Takes 6-10x Longer

Why 3D LiDAR point cloud annotation takes longer
The complexity stems from:
- 3D spatial reasoning: Annotators mentally construct object geometry from sparse points, rotating views and manipulating three orthogonal planes to align boxes precisely
- Sparse data at distance: Point gaps widen at longer ranges, making boundaries ambiguous; ground-object transitions require careful judgment
- Occlusion patterns: Objects hide behind others in 3D space; annotators infer extent from context or track across frames; partial visibility is the norm
- Coordinate complexity: Point clouds transform through multiple frames; misaligned calibration creates systematic errors
In point clouds, you see only geometric shapes made of dots. No color, minimal intensity cues. Distinguishing a small tree from a pedestrian with similar silhouettes at low point density requires skill and 3D imagination.
The cognitive load causes annotation fatigue, requiring three validation rounds (initial labeler, secondary checker, final audit) for safety-critical applications.
3D LiDAR annotation tasks and label formats
Oriented 3D bounding boxes (cuboids) are standard for object detection. Unlike 2D rectangles, oriented cuboids include rotation parameters (yaw, sometimes pitch/roll) to match actual object orientation.
Semantic segmentation assigns a class label to every point in the cloud: road, building, vegetation, vehicle, pedestrian. Per-point labeling uses uint8 or uint16, stored as binary arrays.
Instance segmentation extends semantic labels to distinguish individual objects within the same class, assigning unique tracking IDs. Challenging when objects overlap or sparse data makes boundaries ambiguous.
Panoptic segmentation combines both. Every point gets a semantic class label and instance identifier, distinguishing “things” (countable objects) from “stuff” (amorphous regions).
The annotation format must match your model’s output type. KITTI uses text files; nuScenes uses JSON arrays.
3D LiDAR Annotation Tools and Build vs Buy Decisions
Open-source tool limitations
An open-source 3D LiDAR annotation tool offers starting points but has production limitations:
- CVAT provides multi-view layouts and exports to OpenPCDet/MMDetection3D formats, but 3D capabilities remain basic with no dense segmentation. Requires technical setup and custom integration
- Label Studio handles multiple modalities but 3D support is partial—better for multi-format projects than specialized 3D LiDAR point cloud work
- 3D BAT is purpose-built for full-surround 3D annotation with interpolation, batch editing, and semi-automatic tracking
Professional platform advantages
A professional data annotation platform (Scale AI, Label Your Data, Segments.ai, AWS SageMaker Ground Truth) provides integrated QA, sensor fusion support, one-click cuboid fitting, and AI-assisted pre-labeling. Faster for large-scale work through built-in automation.
The downside is cost. Commercial platforms charge per annotation or per hour, but efficiency often justifies the expense versus managing open-source data annotation tools.
Production workflow criteria:
- Multi-view visualization and sensor fusion support
- Interpolation and pre-labeling/ML assistance
- QA workflows (double-pass audits, inter-annotator agreement)
- Export compatibility (KITTI, nuScenes, OpenPCDet)
In-house vs outsourced decision factors
The decision involves tradeoffs across technical expertise, scalability, iteration speed, data security, and data annotation pricing:
- Technical expertise: 2-3 month training timelines for 3D spatial coordinates, sparse data handling, and occlusion patterns (significantly longer than 2D annotation)
- Scalability: Data collection vehicles gather frames faster than annotators process them. Outsourcing enables parallel workforce scaling
- Data security: AV data requires NDAs, ISO-certified facilities, biometric controls, and deletion protocols (some sensitive data mandates in-house annotation)
Cost structures differ significantly:
| Approach | Direct Costs | Hidden Costs | Scalability |
| In-house | Salaries, tool licenses | Recruiting, 2-3 month training, QA infrastructure, management overhead, idle capacity | Limited by headcount |
| Outsourcing | ~$4/hour for specialists, custom pricing | Vendor management, data transfer, guideline development | Parallel workforce scaling |
The hybrid approach works for many teams. In-house for initial ontology development, edge case handling, and QA validation; outsource to 3D LiDAR annotation services for bulk annotation and scaling during peak periods.
This balances expertise development with production throughput.
One telling consideration: doing everything in-house without expert data annotation company support can cause you to fall behind. If annotation becomes the bottleneck for model iteration, consider whether saving on cost is worth being last to market.
4D LiDAR: An Emerging Capability Worth Monitoring
4D LiDAR adds instantaneous velocity using Frequency Modulated Continuous Wave (FMCW) technology. Instead of measuring pulse round-trip time, FMCW sensors measure Doppler shift.
Higher frequency means approaching objects, lower means receding.
The technology offers weather resilience, interference immunity, and direct velocity measurement. Limitations include measuring only radial velocity, lower maturity than ToF alternatives, and higher costs.
For annotation pipelines, 4D LiDAR adds velocity as a per-point attribute, requiring schema updates but potentially simplifying motion tracking annotations. For most machine learning teams in 2024-2025, 4D LiDAR data remains rare. Traditional 3D mapping LiDAR with ToF sensors dominates surveying and infrastructure applications.
About Label Your Data
If you choose to delegate 3D LiDAR annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
How does 3D LiDAR work?
LiDAR works through time-of-flight measurement. The sensor emits laser pulses, measures how long they take to bounce back from surfaces, and calculates distance. By scanning across multiple angles (using rotating mechanisms or MEMS mirrors), it builds a 3D point cloud of the environment.
Is 4D LiDAR better than 3D LiDAR?
4D LiDAR adds instantaneous velocity measurement (the fourth dimension) using FMCW technology, which measures Doppler shift instead of time-of-flight. This provides direct velocity data per point and better weather performance.
However, it’s more expensive, less mature, and currently measures only radial velocity. For most applications in 2024-2025, 3D LiDAR with sensor fusion provides sufficient performance.
How accurate is LiDAR 3D scanning?
Modern automotive LiDAR achieves centimeter-level accuracy, typically ±2-3 cm under good conditions. Accuracy degrades with distance, weather (rain/fog), and surface reflectivity. High-end systems maintain sub-centimeter precision at close range.
What are the top 3D LiDAR cameras?
Top 3D LiDAR scanner manufacturers include Velodyne (VLP-16, HDL-64E for established mechanical rotating sensors), Ouster (OS1, OS2 series for digital LiDAR with high resolution), Luminar (Iris for long-range automotive applications using 1550nm wavelength), Livox (Mid-360, Avia for cost-effective non-repetitive scanning patterns), and Hesai (Pandar series, widely adopted in Chinese autonomous vehicle market).
The choice depends on range requirements, point density needs, budget, and application context. Automotive systems prioritize range and reliability, while robotics applications often favor cost and compact form factors.
Why does Elon Musk refuse to use LiDAR?
Tesla’s position is that cameras plus AI can achieve autonomous driving at lower cost and better scalability than LiDAR-based systems. Musk argues that humans drive using vision alone, so cameras with sufficient neural network training should suffice. However, Tesla has purchased LiDAR sensors for testing, and the rest of the autonomous vehicle industry uses sensor fusion (LiDAR + cameras + radar) for safety-critical systems.
How to create 3D models using LiDAR?
- Capture point cloud data with LiDAR sensor
- Clean and filter noise/outliers from raw data
- Align multiple scans if needed (registration)
- Process with software (CloudCompare, MeshLab, specialized tools)
- Generate mesh from points (Poisson surface reconstruction)
- Apply texture mapping if RGB data available
- Export to CAD or 3D modeling formats
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.