Satellite Image Annotation: Ground Truth for Geospatial AI

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What Makes Satellite Image Annotation Different From Standard Computer Vision?
- Core Annotation Types for Satellite ML Pipelines
- What Technical Requirements Break or Make Satellite Image Annotation?
- How We Solved Annotation Challenges in Production Geospatial AI
- How Foundation Models Change Satellite Image Annotation Workflows
- How to Validate Satellite Imagery Annotation Quality Before Deploying Your Model
- About Label Your Data
-
FAQ
- What is satellite imagery annotation?
- Why can't I use standard computer vision annotation for satellite data?
- What's the difference between semantic segmentation and object detection for satellite imagery?
- How do I validate satellite image annotation quality before training?
- What annotation accuracy should I expect for production geospatial AI?
TL;DR
- Satellite data requires coordinate system preservation, spectral band interpretation, and handling 360° object rotation.
- Low IoU annotations (0.5) cause production failures when models deploy to new geographic regions or encounter edge cases.
- Validate annotation quality by sampling 100 annotations for IoU checks and verifying CRS preservation before training.
Your satellite imagery needs labeled ground truth, but standard computer vision assumptions don't apply.
Coordinate systems must stay intact through annotation. Annotators interpret spectral bands your eyes can't see. Objects rotate 360 degrees in overhead views, and cloud-free machine learning datasets often contain thin cirrus most annotators miss.
Bad annotations mean your model hits 0.5 IoU in training but fails at 0.3 in new regions. This article shows you which data annotation types work for geospatial pipelines, which technical requirements break models, and how to validate quality before training on bad labels.
What Makes Satellite Image Annotation Different From Standard Computer Vision?
Resolution and scale challenges
A single satellite image can span 10,000 x 10,000+ pixels covering 100+ square kilometers. If you're training vehicle detection, you need sub-meter resolution where cars occupy roughly 15 pixels. But if you're doing land cover classification, you're probably working at 10-30 meter resolution across regional scales.
Here's where it gets painful: mismatch between training and inference resolution kills your model.
Train on 10-meter Sentinel-2 data, then try to run inference on 0.5-meter WorldView imagery? Your accuracy will crater. This isn't a minor degradation: ResNet trained on natural images hits only 55% accuracy on aerial crops versus 82% when you train it on aerial data from the start.
Standard annotation platforms will happily export your labels without any geospatial-aware tiling logic, leaving you to manually stitch predictions and handle boundary artifacts.
Coordinate reference systems matter
You've probably hit this frustration: you get annotations back, load them into your GIS stack, and nothing lines up. The polygons are there, but they're not georeferenced.
Your annotations need embedded coordinate information to map back to Earth's surface. WGS84 (EPSG:4326) works for global latitude/longitude. UTM gives you zone-based metric projections for local analysis. The specific system matters less than ensuring it's preserved through the entire annotation workflow.
The problem here is that most standard data annotation tools strip geospatial metadata during export. You end up manually rebuilding spatial references, which defeats the purpose of outsourcing annotation in the first place.
Look for workflows that support Cloud-Optimized GeoTIFF (COG) input and can export with embedded CRS information your pipeline can actually use.
Multi-spectral complexity
If you're working with Sentinel-2, you know RGB is just 3 of 13 bands. Your model needs NIR to understand vegetation health, SWIR to detect moisture, maybe thermal for heat signatures.
But here's the annotation issue: your annotators are looking at false-color composites to interpret non-visible spectra. A forest that looks healthy in RGB might show stress patterns in NIR.
Without training in spectral signatures, annotators will mislabel based purely on what they see in visible light.
Generic crowdsourcing platforms assign annotators with zero spectral band knowledge. Whether working with satellite vs. drone imagery, annotators need training in false-color composites and band interpretation.
You can't just hand someone a Sentinel-2 scene and expect accurate labels. They need to understand NDVI values, band combinations, and spectral signatures for different land cover types. Otherwise, you're training your model on systematically wrong labels.
Core Annotation Types for Satellite ML Pipelines
Semantic segmentation for land cover classification
If you're doing pixel-level machine learning classification across large areas, you need clean semantic segmentation masks. This map labeling process requires image tiling with proper overlap handling.
Your U-Net or DeepLab model will learn whatever boundary artifacts you feed it. Sloppy polygon edges or inconsistent handling where tiles meet? That propagates through your entire model. You want edge smoothing and careful tile stitching, not jagged boundaries that create prediction artifacts.
Benchmarks like BigEarthNet give you 590k+ labeled patches to compare against. But when you're creating custom training data, the quality of those polygon boundaries matters more than sheer volume.
For annotation tool options and workflows, see this satellite image annotation repository covering deep learning applied to satellite and aerial imagery
Object detection with oriented bounding boxes
Standard image recognition approaches like YOLO or Faster R-CNN expect objects with fixed orientation. That doesn't work when you're looking down from space.
You need oriented bounding boxes that capture rotation angle alongside position and size. If you're using mmrotate, R3Det, or S2ANet, your ground truth format needs to match what these frameworks expect.
Small object detection makes this harder. When vehicles cover roughly 15 pixels, a 5-degree rotation error in your annotations compounds across thousands of training examples. Sloppy rotated boxes degrade accuracy fast.
Similar challenges exist for annotating whales in VHR satellite imagery, where systematic scanning protocols at 1:1500 scale help maintain annotation consistency.
Change detection annotation
Your temporal workflow needs paired images with change masks. You're tracking what changed between time A and time B: maybe new construction, deforestation, or flood extent.
In this case, you need spatial alignment between image pairs, temporal consistency in how features are labeled, and often semantic distinction between types of change. "Newly built" versus "demolished" as separate classes, not just generic "change."
Most annotation platforms can't handle this workflow properly. They lack tools to load image pairs, keep them spatially registered, and enforce temporal logic in labels.
You end up with inconsistent annotations where the same building gets different labels across time periods.
If you're working with time series (5+ temporal snapshots), data annotation pricing multiplies. Recent semi-supervised methods can hit 90% accuracy with only 10% labeled data — but that 10% needs to be temporal pairs with perfect alignment and consistency.
SAR annotation
Synthetic Aperture Radar (SAR) works through clouds and darkness, which makes it valuable for monitoring applications that can't wait for clear weather. But SAR imagery doesn't look like optical data: speckle noise and backscatter physics mean you need annotators who understand radar signatures, not just visual patterns.
If you're doing ship detection, flood mapping, or ground deformation measurement, you need people who know that metallic structures, water, and vegetation produce characteristic backscatter regardless of what they "look like."
This is a market gap. Defense contracts get SAR annotation services, but commercial ML teams struggle to find a data annotation company with actual radar domain expertise.
For a deeper dive into polygon annotation, object detection, and semantic segmentation workflows, check out our complete geospatial annotation guide.
What Technical Requirements Break or Make Satellite Image Annotation?
Resolution requirements by application
Your model performance in satellite imagery analysis depends on matching training resolution to deployment needs.
Here's what different applications actually require:
| Application | Resolution Needed | Common Sources |
| Vehicle/ship detection | Sub-meter (<0.5m) | WorldView-3, Maxar |
| Building footprints | 0.5-2m | Planet SkySat |
| Land cover classification | 10m | Sentinel-2 |
| Regional analysis | 30m | Landsat-8/9 |
Train on 10-meter data, then deploy on sub-meter imagery? Expect significant accuracy drops. Your training resolution needs to match or exceed what you're using at inference.
Accuracy benchmarks and IoU thresholds
You're probably used to 0.5 IoU being "good enough" in standard computer vision. For production geospatial systems, like infrastructure monitoring or defense applications, you want 0.9+ IoU.
Quality control matters more here than in general object detection. Look for annotation workflows that include:
- Inter-annotator agreement checks (Cohen's Kappa for classification, IoU for polygons)
- Calibration datasets where annotators must hit >90% accuracy before production work
- Multi-stage review (not just one person checking their own work)
At Label Your Data, we use multi-stage verification to guarantee 98%+ accuracy. That level of precision prevents the downstream issues where your model learns annotation errors as real patterns.
Edge cases that degrade computer vision satellite imagery models
Cloud cover affects most optical satellite imagery. Your annotators need to distinguish between clear sky, thin clouds, thick clouds, and cloud shadows (because each impacts your model differently).
Thin cloud detection is the hardest annotation task in satellite imagery, and cloud shadows are even trickier than the clouds themselves.
Off-nadir angles change both resolution and geometry. Images captured straight down (nadir) give you better resolution than images captured at an angle. More importantly, models trained on nadir imagery often fail on off-nadir data, even for the same targets.
Geographic domain shift causes dramatic accuracy drops. Train your model on European data, deploy it in Africa, and watch accuracy fall from 90% to below 50% for identical feature types.
Seasonal variation means winter imagery looks completely different from summer imagery in spectral signatures.
Your annotation strategy needs to deliberately sample difficult cases. Otherwise, your model learns on best-case scenarios and fails in production.
How We Solved Annotation Challenges in Production Geospatial AI

These are real projects we’ve been working on at Label Your Data where data annotation services quality directly impacted model performance in production.
Landfill detection model validation for Yale University
PhD students from Yale needed to validate Random Forest and XGBoost models detecting landfills in satellite imagery. The technical challenge lied in distinguishing actual landfills from recycling facilities, quarries, and animal feeding operations that look similar from space.
The annotation complexity came from varying image quality: cloud cover, temporal gaps, missing data for certain time periods. Our annotators had to identify trash piles and plastic across 10,400 coordinates in 16 global locations.
Quality protocol used cross-reference validation: two annotators worked simultaneously with confidence scoring. If they disagreed, a third reviewer made the final call.
Addressing the unbalanced class problem through strategic sampling made the difference:
- Model performance jumped significantly
- Random Forest AUC went from 82-84 to 92
- XGBoost hit 94+
Active learning through probabilistic coordinate selection based on model uncertainty maximized each labeled example's impact on model improvement.
Land cover classification for geospatial AI company
A US geospatial intelligence firm needed to scale annotation for earth-sensor mapping products. They had model-generated pre-labels that needed human correction and expansion.
Our team handled 23,000+ images over a year with rolling batches. We split 37 annotators across two teams: one for initial annotation, one for corrections. We used CVAT with structured QA reviews at each stage before the client received deliveries.
Results:
- Main classification accuracy jumped from 0.81 to 0.91
- Feature detection went from 0.75 to 0.87
More importantly, deployment accelerated by several months because the client could trust the labels without extensive internal review.
The scalability mattered most. When they landed larger contracts, elastic annotation capacity meant they could take on projects that would have been impossible with their internal team alone.
Polygon annotation for palm tree detection aerial imagery
KAUST needed high-resolution aerial imagery annotated in QGIS for agricultural monitoring research. They turned to Label Your Data with a challenge: overlapping canopies and irregular tree crowns made polygon boundaries difficult to define consistently.
We used a single dedicated annotator for consistency, starting with a pilot phase where the client reviewed the first 10% before scaling. QA layers in QGIS caught errors before delivery.
Results:
- 98%+ accuracy verified by the client
- 17-day delivery for the complete dataset
The dataset generalized well across regions, which improved research reliability. More importantly, researchers could focus on model development instead of cleaning up inconsistent labels.
The workflow integrated directly with their existing GIS stack using native QGIS, eliminating format conversion steps.
How Foundation Models Change Satellite Image Annotation Workflows
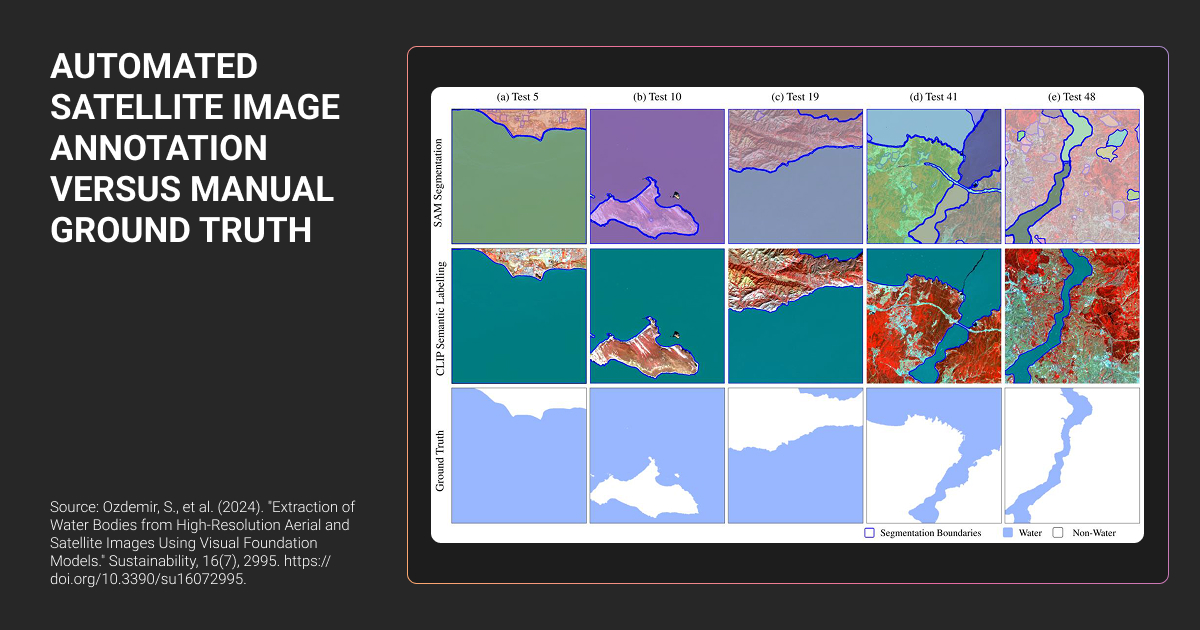
You've probably heard about SAM2 and NASA's Prithvi model. Here's what they actually do for your satellite image annotation workflow.
Pre-annotation with SAM2 and Prithvi
SAM2 via segment-geospatial can cut your polygon annotation time by roughly 3×. Instead of manually drawing every boundary, you give it point prompts or rough boxes, and it generates initial masks.
NASA-IBM's Prithvi, trained on massive Landsat-Sentinel data, lets you fine-tune with 90% fewer labels than training from scratch.
The practical workflow looks like this: foundation model generates pre-annotations → human expert refines boundaries → QC validates the final output.
But here’s where automation fails: cloud versus cirrus distinction, building versus greenhouse confusion, seasonal variation. Foundation models weren't trained on edge cases, so they struggle with the same ambiguous scenarios that trip up your production models.
Foundation models amplify bad annotations. If your small labeled set contains errors, those propagate through the entire machine learning algorithm during fine-tuning.
Cost trade-off for a typical project: 10 hours manual annotation versus 2 hours SAM2 refinement plus 1 hour QC. The ROI depends on your dataset size and feature complexity. Skip pre-annotation for small datasets (under 500 images) or highly specialized features where foundation models lack relevant training data.
Few-shot learning combined with transfer learning works well for rare object detection. Train a model on broad satellite imagery first, then fine-tune using limited examples of your target object. The model leverages general visual features while adapting to specific edge cases with minimal labeled data.

 Director of Business Development, PayCompass
Director of Business Development, PayCompass
Foundation models reduce manual work, but you still need a data annotation platform that preserves geospatial metadata and supports iterative refinement workflows.
How to Validate Satellite Imagery Annotation Quality Before Deploying Your Model
You need to catch annotation errors before you waste GPU hours training on bad labels.
Pre-deployment quality checks
Visual spot-checking isn't enough to validate annotation quality. Sample 100 random annotations and measure IoU against your own re-annotation to establish baseline quality before committing to the full dataset.
Check class distribution for annotation bias; if you see 90% "building" labels and only 10% "road," that signals a problem rather than reflecting actual ground truth. Zoom into polygon boundaries to spot staircase artifacts from rushed work.
For change detection projects, verify temporal consistency by ensuring the same location shows coherent semantics across time periods rather than random class flipping between dates. Test format integrity by importing annotations into QGIS or ArcGIS to confirm coordinates align and CRS information is preserved, which catches vendors who strip geospatial metadata during export.
Watch for red flags: vendors who can't provide sample QC reports, refuse format verification, or lack inter-annotator agreement metrics. If they deliver 10,000 labels but 30% fail your IoU validation, you have a significant quality problem.
When public datasets lack rare objects, we extend with synthetic data using 3D assets and GANs. Research shows six real labeled examples can achieve high recall with quality synthetic data. We pair this with active learning: the model identifies uncertain examples, humans annotate only that high-value data.
 Founder & CEO, CISIN
Founder & CEO, CISIN
When to re-annotate versus when to augment
Re-annotate when model accuracy falls below 70%, geographic variance is high, or edge cases fail completely, since training data bugs cause persistent errors that augmentation can't resolve.
For example, cloudy images mislabeled as "clear" teach your model that cloud patterns represent valid surface features, and adding more data won't correct this fundamental error.
The cost comparison matters: re-annotating 1,000 images at $2 each ($2,000) versus collecting 5,000 new images or accepting reduced accuracy.
Augmentation works when labels are correct but you need more volume, better class balance, or improved edge case coverage. Active learning optimizes this approach by deploying your model to identify high-uncertainty predictions, then annotating those specific cases rather than random samples.
Label Your Data supports iterative workflows that allow targeted re-annotation based on model performance feedback rather than requiring batch-only delivery.
About Label Your Data
If you choose to delegate satellite image annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is satellite imagery annotation?
Satellite imagery annotation is the process of labeling features in satellite data to create training datasets for machine learning models.
This includes drawing polygons around land cover types, placing oriented bounding boxes on vehicles or ships, marking temporal changes between image pairs, and preserving geospatial metadata like coordinate reference systems throughout the workflow.
Why can't I use standard computer vision annotation for satellite data?
Satellite data requires coordinate system preservation, multi-spectral band interpretation (NIR, SWIR, thermal), and handling 360-degree object rotation in overhead views. Standard annotation tools strip geospatial metadata during export, annotators lack spectral signature training, and workflows don't support temporal pairs for change detection.
What's the difference between semantic segmentation and object detection for satellite imagery?
Semantic segmentation assigns pixel-level classes across large areas (agricultural boundaries, land cover classification) requiring clean polygon edges and proper tile stitching.
Object detection identifies specific targets (vehicles, ships, buildings) using oriented bounding boxes that capture rotation angles, essential for overhead imagery where objects appear at any orientation.
How do I validate satellite image annotation quality before training?
Sample 100 random annotations and measure IoU against your own re-annotation. Check class distribution for bias, zoom into polygon boundaries for staircase artifacts, verify temporal consistency for change detection, and test format integrity by importing into QGIS/ArcGIS to confirm CRS preservation. Red flag vendors who can't provide QC reports or inter-annotator agreement metrics.
What annotation accuracy should I expect for production geospatial AI?
Production systems target 0.9+ IoU for critical applications versus 0.5 IoU standard in general computer vision.
Quality protocols should include multi-stage verification, inter-annotator agreement checks (Cohen's Kappa for classification, IoU for polygons), and calibration datasets where annotators achieve >90% accuracy before production work.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.