Synthetic Data vs Real Data: When Each Works (and When It Fails)

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Why ML Teams Can't Settle the Debate Between Synthetic vs Real Data
- Synthetic Data vs Real Data Differences, Pros, and Use Cases
- How Reliable Is Synthetic Data for ML Model Training?
- Where Synthetic Data Works Best
- Advantages of Synthetic Data in ML Pipelines
- Where Synthetic Data Falls Short
- Why Real Data Is Still Irreplaceable
- When to Use Synthetic Data vs Real Data in Machine Learning
- How to Combine Synthetic and Real Data in Practice
- About Label Your Data
- FAQ

TL;DR
- Synthetic data works well for computer vision, LLM fine-tuning, and robotics, but models trained only on synthetic data typically perform worse than hybrid approaches that include real data.
- The domain gap between simulated and real-world data is shrinking with foundation models, but it remains a major source of failure in production ML systems.
- ML teams that validate and audit synthetic datasets like real data achieve better model performance than teams that rely on auto-generated labels without review.
Most machine learning systems fail not because of model architecture, but because teams lack enough high-quality labeled data.
Collecting and labeling datasets takes time, costs money, and is often restricted by privacy regulations. As models grow more complex, the demand for high-quality training data continues to increase.
Synthetic data offers an alternative. Instead of collecting real-world samples, teams generate datasets programmatically using simulations or generative models.
But synthetic data is not a universal solution. In most real-world systems, it works best as a supplement to real data rather than a replacement. The most reliable ML pipelines combine both.
Understanding the tradeoffs between synthetic data vs real data helps ML teams design training pipelines that balance scalability with real-world accuracy.
Why ML Teams Can't Settle the Debate Between Synthetic vs Real Data

Data collection rarely scales as quickly as model development.
Labeling datasets through data annotation is often expensive and slow. Privacy regulations restrict access to many valuable datasets, including medical records, financial transactions, and user behavior data.
Synthetic datasets allow organizations to simulate rare events and expand limited machine learning datasets:
- Microsoft trained Phi-4 on 50+ synthetic datasets and outperformed models 5x its size on math benchmarks.
- NVIDIA generates tens of thousands of synthetic warehouse images in hours using Omniverse.
- Waymo simulates dangerous driving scenarios (tornadoes, wrong-way drivers, flooded streets) that would be impossible to capture safely on real roads.
However, real-world results are mixed. Models trained heavily on synthetic datasets may perform well in benchmarks but struggle when exposed to real-world inputs.
The core challenge is the domain gap between simulated environments and real-world data.
I learned this while doing penetration testing: synthetic scenarios found infrastructure weaknesses, but real user data revealed that 40% of breaches came from credential issues we never thought to simulate.

 Managing Partner, Sundance Networks
Managing Partner, Sundance Networks
Synthetic Data vs Real Data Differences, Pros, and Use Cases
The difference between synthetic data vs real data is how the dataset is created. Synthetic data is generated artificially using simulations or generative models, while real data is collected from real-world systems, users, or sensors.
The synthetic data vs real data comparison usually comes down to realism, scalability, privacy, and validation.
| Factor | Synthetic Data | Real Data |
| Data source | Generated by simulations or generative models | Collected from real-world systems |
| Scalability | Large datasets can be generated quickly | Limited by collection and annotation costs |
| Privacy risk | Low because no real user data is exposed | Higher when datasets contain sensitive data |
| Realism | Depends on simulation accuracy | Captures real-world complexity and noise |
| Validation | Must be tested against real datasets | Serves as the benchmark for model performance |
Synthetic datasets are particularly useful when collecting real data is expensive, restricted, or rare. Simulations can generate edge cases for autonomous vehicles, robotics training environments, or instruction datasets for language models.
However, real datasets remain essential for validating model performance. Simulations rarely capture every variable present in production environments, such as sensor noise, unpredictable user behavior, or rare edge cases.
For this reason, most ML systems rely on hybrid datasets that combine synthetic and real data.
How Reliable Is Synthetic Data for ML Model Training?
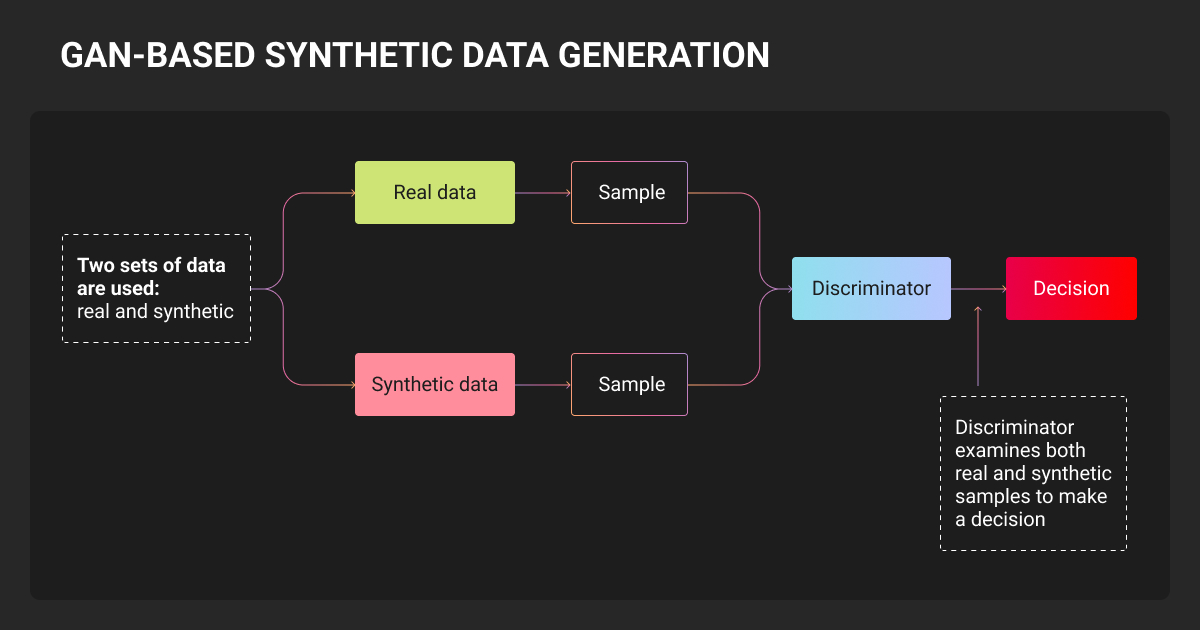
Synthetic data vs. real data refers to two different sources of training datasets used in machine learning.
Both approaches are widely used in modern ML pipelines, but they serve different purposes. Synthetic datasets provide scale and coverage, while real datasets capture real-world complexity and unpredictability.
Synthetic data can be highly effective in some domains and unreliable in others. Its usefulness depends on three factors:
- The domain being modeled
- The quality of the data generation process
- Whether models are validated using real-world data
Before looking at specific use cases, it helps to understand how these datasets differ across several core dimensions.
Where Synthetic Data Works Best
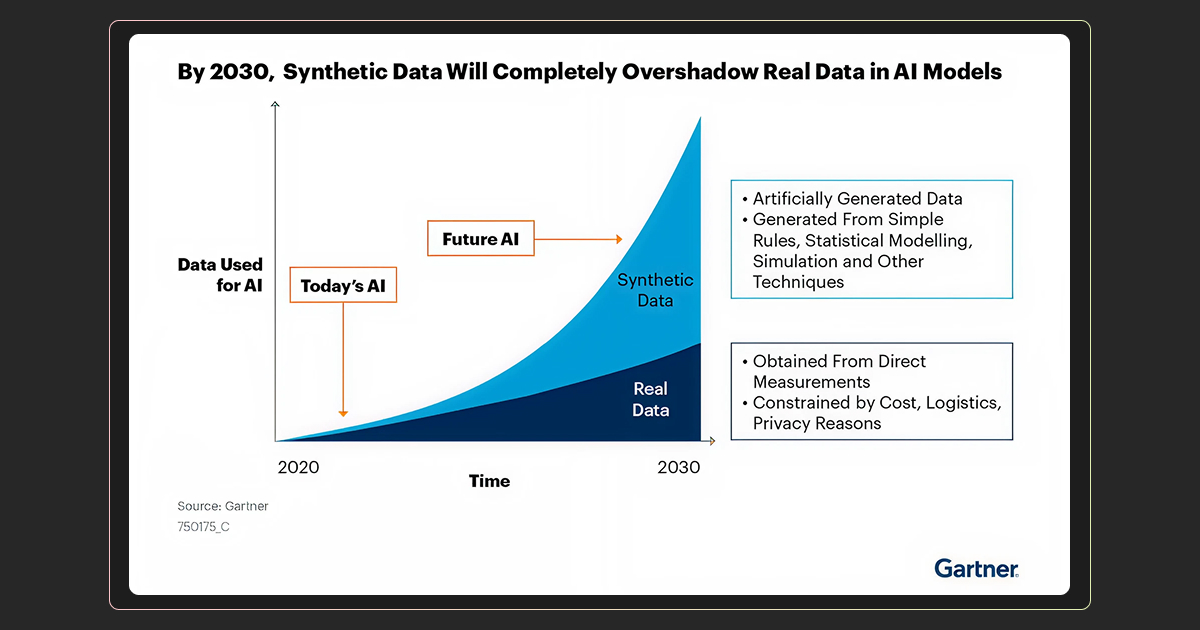
A common strategy is to pre-train models on synthetic datasets and then fine-tune them on real data. This workflow is widely used in computer vision, robotics, and large language models.
Computer Vision
Computer vision has one of the strongest production track records for synthetic datasets.
Simulation environments can generate large labeled datasets for image recognition models by varying lighting, object placement, textures, and camera angles. These variations help models learn robust visual features before being fine-tuned on smaller sets of real images.
NVIDIA’s Omniverse Replicator pipeline illustrates the approach: starting from just 50 real images, augmented with 1,000 synthetic samples, it achieved 94.5% mAP on defect detection.
LLM Fine-Tuning
Synthetic datasets also play an important role in LLM fine tuning.
In many pipelines, a stronger language model generates structured examples such as instruction-response pairs or reasoning steps. These examples are then used to train smaller models.
Because text data can be generated quickly and evaluated automatically, synthetic datasets are especially useful for instruction tuning and model distillation.
Robotics and Simulation Training
Robotics research relies heavily on simulation environments.
Training robots entirely in the real world is slow, expensive, and potentially dangerous. Simulations allow researchers to run thousands of experiments in parallel.
By introducing variation into simulated environments, models can learn policies that transfer more effectively to real-world systems.
Synthetic data works well for increasing coverage (rare scenarios, long-tail edge cases) and privacy-sensitive domains. But you still need real annotated data to anchor to the true distribution, especially for evaluation and catching 'unknown unknowns' in production.
 AI & Data Platform Leader
AI & Data Platform Leader
Advantages of Synthetic Data in ML Pipelines
Synthetic data has become popular because it addresses several challenges in machine learning pipelines.
One key advantage is scalability. Synthetic datasets can be generated quickly and in large quantities, allowing teams to expand limited training datasets without collecting additional real-world data.
Another advantage is privacy protection. Because synthetic datasets do not contain real user records, they can be used to train models without exposing sensitive information.
Synthetic data is also valuable for simulating rare events. In many real-world datasets, important scenarios occur infrequently. Synthetic generation allows teams to create targeted examples for these edge cases.
Finally, simulation environments enable controlled experimentation. Researchers can systematically vary environmental conditions to better understand model behavior.
Where Synthetic Data Falls Short
Despite these advantages, synthetic datasets introduce several risks.
Domain Gap
The largest challenge is the domain gap, the difference between simulated environments and real-world data.
For example, a computer vision model trained on simulated driving scenes may struggle with real-world glare, weather conditions, or camera sensor noise that were not modeled in the simulation.
Even small differences between synthetic and real datasets can significantly reduce model performance.
Model Collapse
Model collapse occurs when models repeatedly train on AI-generated data instead of real datasets.
Over time, the diversity of the dataset decreases and outputs become increasingly repetitive. A 2024 Nature study confirmed this effect within 3-5 training generations.
Maintaining real datasets helps prevent this problem.
Bias Amplification
Synthetic datasets can amplify data bias.
If the original data used to train generative models contains imbalances, the generated data may reproduce and even exaggerate those patterns.
Without careful validation, synthetic pipelines can reinforce existing dataset biases.
Hidden Engineering Costs
Synthetic data is sometimes described as inexpensive, but building reliable generation pipelines requires significant engineering effort.
Teams must design simulation environments, validate generated outputs, and ensure models trained on synthetic datasets generalize to real-world conditions.
When budgeting for either approach, teams should compare synthetic pipeline costs against data annotation pricing for real datasets. In many cases, the gap is smaller than expected.
Why Real Data Is Still Irreplaceable
Synthetic data can reproduce patterns that are already known, but it struggles to capture unknown or unpredictable factors. Real datasets contain subtle signals that simulations often miss, including sensor noise, rare defects, and unexpected user behavior.
These details often determine whether a model performs reliably outside controlled benchmarks.
Real annotated datasets also remain the most reliable benchmark for evaluating model performance.
When to Use Synthetic Data vs Real Data in Machine Learning
The choice between real data vs synthetic data depends on the problem domain and stage of the ML pipeline.
Use synthetic data when:
- collecting real-world data is expensive or restricted
- you need to simulate rare edge cases
- privacy regulations limit access to sensitive datasets
Use real data when:
- models must operate in unpredictable environments
- reliable evaluation benchmarks are required
- subtle real-world patterns affect model performance
Most production ML systems combine both approaches, often partnering with a data annotation company like Label Your Data to ensure real data quality meets the standard needed for validation.
Synthetic data works well for initial tests when you need to protect client privacy. The problem is it can be too clean and predictable. Real-world data shows you the weird edge cases and silent failures. I use synthetic data to start fast, but you always need a phase with real data to catch the stuff that trips you up.
 Co-Founder and CEO, AthenaHQ
Co-Founder and CEO, AthenaHQ
How to Combine Synthetic and Real Data in Practice
Hybrid pipelines often deliver the best results.
Synthetic datasets provide scale and coverage, while real datasets ensure models remain grounded in real-world conditions.
Validating and Annotating Synthetic Datasets
Automatically generated labels are not always correct. Simulation pipelines can produce subtle labeling errors, including:
- bounding box misalignment
- inconsistent segmentation masks
- incorrect label granularity
Synthetic datasets should therefore be validated using the same data annotation tools used for real datasets.
A typical validation workflow includes:
- Defining a consistent labeling taxonomy
- Validating synthetic labels against that taxonomy
- Running automated consistency checks
- Testing model performance on real holdout datasets
- Maintaining human review for edge cases
Pre-train on Synthetic, Fine-Tune on Real Data
Synthetic pre-training helps models learn general patterns and structural features. Fine-tuning on real datasets then adapts those patterns to real-world conditions.
Regardless of training strategy, models should always be evaluated on real-world test datasets.
Synthetic data can help scale machine learning pipelines, but it works best when paired with high-quality real data. Many teams rely on data annotation services to validate both synthetic and real datasets before deploying models in production.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Check our performance based on a free trial
Pay per labeled object or per annotation hour
Working with every annotation tool, even your custom tools
Work with a data-certified vendor: PCI DSS Level 1, ISO:2700, GDPR, CCPA
FAQ
What is an example of synthetic data?
Synthetic data can include simulated images used in computer vision training, text generated by language models for instruction datasets, or tabular datasets that replicate the statistical structure of real data.
What are the disadvantages of synthetic data?
Synthetic data may fail to capture real-world complexity, which can create domain gaps between simulated and real environments. It can also amplify bias or introduce labeling errors if datasets are not carefully validated.
What is one advantage of using synthetic data over real data?
Synthetic data allows teams to generate large labeled datasets quickly without exposing sensitive real-world data, making it useful when privacy restrictions, cost, or rare edge cases limit access to real datasets.
What is the difference between synthetic data and sample data?
Sample data is a subset of real-world observations drawn from an existing dataset. Synthetic data is generated artificially to mimic statistical properties of real datasets without containing actual records.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.