Few-Shot Learning: How Models Learn from Limited Data

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What Is Few Shot Learning?
- Why Few Shot Learning Matters for Limited Data Problems
- How Does Few-Shot Learning Work?
- Comparing Few Shot Learning Approaches in Machine Learning
- Real-World Applications and Few-Shot Learning Examples
- Few Shot Learning Challenges and Limitations
- Data Preparation for Few-Shot Learning
- How to Implement Few-Shot Learning Models
- Choosing Your Few-Shot Learning Approach
- About Label Your Data
- FAQ

TL;DR
- Few-shot learning hits 76-81% accuracy with just 5-10 examples per class instead of thousands.
- Pre-trained models with basic classification often outperform complex meta-learning, so try transfer learning before building sophisticated systems.
- With only 5 support examples, one mislabeled image tanks performance, making expert annotation necessary rather than optional.
Public datasets don’t fit custom use cases, and collecting thousands of labeled examples per class isn’t realistic for most ML teams.
Few shot learning (FSL) trains machine learning models to classify from minimal examples by learning patterns across many small tasks rather than memorizing one large dataset.
This guide explains metric-based, optimization-based, and transfer learning approaches with real performance benchmarks and when to use each method.
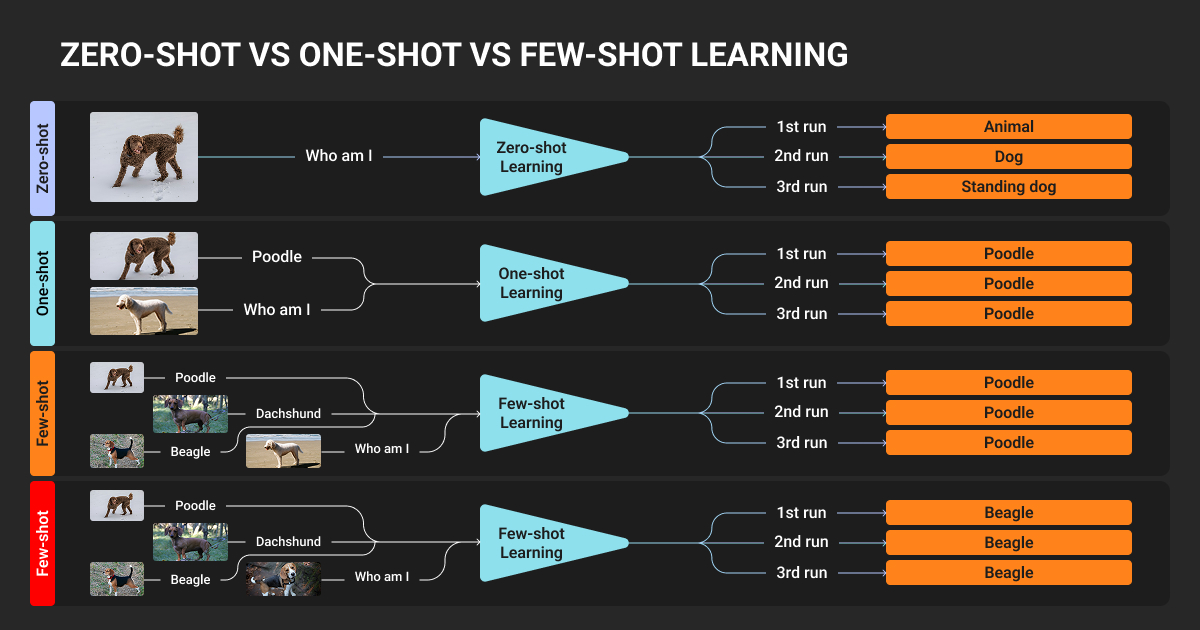
What Is Few Shot Learning?
Few-shot learning AI trains models to generalize from 1-10 labeled examples per class by extracting transferable representations across related tasks.
For example, instead of showing a model thousands of dog images and thousands of cat images until it learns to distinguish them, FSL meta-trains on hundreds of small classification tasks, teaching the model how to learn classification or image recognition patterns in general.
N-way K-shot classification
FSL problems use N-way K-shot notation:
- N = number of classes
- K = labeled examples per class
- Support set = N×K labeled training examples
- Query set = unlabeled test examples
Common benchmarks include 5-way 1-shot (5 classes, 1 example each) and 5-way 5-shot (5 classes, 5 examples each).
One shot vs few shot learning differs in K value: one-shot uses K=1 (single example per class), while few-shot typically uses K=5-10 examples per class for improved accuracy.
Episode-based training simulates test conditions by sampling random N-way K-shot tasks during training. Each iteration picks N random classes and K examples per class. The model sees thousands of these small tasks, learning the general pattern of how to solve them rather than memorizing specific classes.
Meta-train and meta-test classes are completely separate. Training uses 64 ImageNet categories, testing uses 20 different categories (standard miniImageNet split). This tests real generalization, not memorization.
Why Few Shot Learning Matters for Limited Data Problems
The data problem ML engineers face
Custom use cases rarely fit public datasets. You need classification for proprietary products, specialized defect types, or domain-specific categories.
Collecting and labeling thousands of examples per class can take months and require a significant data annotation budget.
For specialized domains, the problem gets worse:
- Rare diseases have limited confirmed cases globally
- New manufacturing defects emerge constantly
- Expert annotation (radiologists, domain specialists) requires significant time and budget
- Privacy constraints limit medical and proprietary data sharing
FSL addresses this by working with the limited data you can actually obtain.
When you need few-shot learning
Few-shot learning becomes necessary for inherently rare events where examples don’t exist at scale. Or privacy-constrained scenarios where data can't be shared or pooled. And constantly evolving categories where waiting months for new data isn't viable.
Also, while data annotation pricing for thousands of examples per class can be substantial, FSL reduces volume requirements significantly. Yet, this makes expert data annotation providers practical and cost-effective for specialized domains.
How Does Few-Shot Learning Work?
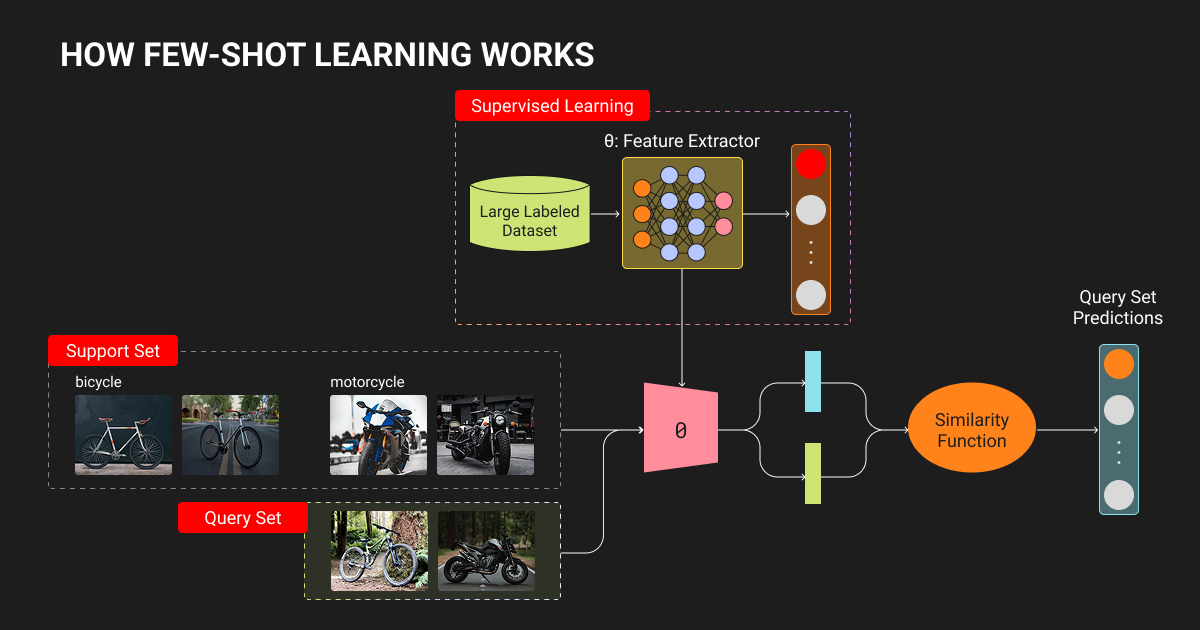
According to Parnami & Lee's survey of few-shot learning techniques and approaches, these methods achieve 68-81% accuracy on standard benchmarks with just 5 examples per class.
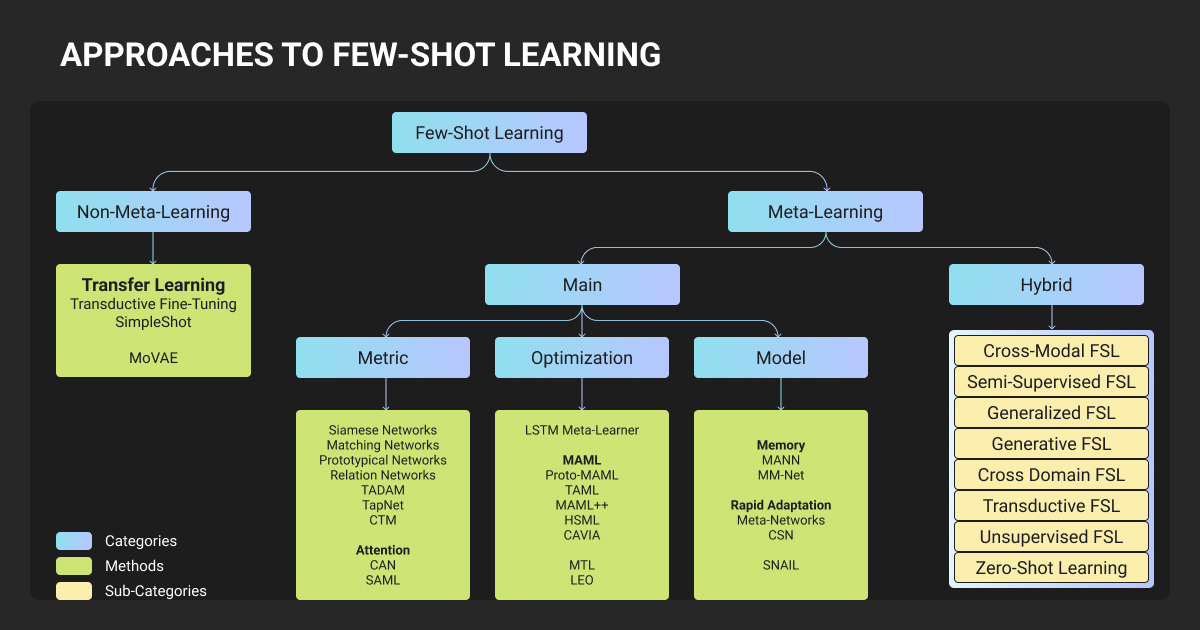
Metric-based meta-learning
Metric-based approaches learn an embedding space where similar examples cluster together, then classify queries by measuring distance to support set examples. No gradient updates happen at test time, making inference fast.
Prototypical networks compute a prototype for each class by averaging support set embeddings, then classify queries by Euclidean distance to prototypes. This achieved 68.2% on miniImageNet 5-way 5-shot.
The method works well because:
- Fast inference under 50ms
- Prototypes update incrementally as support sets grow
- Similarity-based decisions are interpretable
TADAM improves on this by making embeddings task-specific. Bird classification needs texture features, car classification needs shape features. TADAM uses task embeddings to modulate which features matter, achieving 76.7% on miniImageNet 5-way 5-shot.
SimpleShot showed something surprising: using a pre-trained ResNet with L2 normalization and nearest centroid classification achieves 81.5% on the same benchmark without any meta-training.
If you have a good pre-trained encoder for your domain, this baseline often works better than complex meta-learning.
Optimization-based meta-learning
Optimization-based methods learn initialization parameters that enable rapid fine-tuning to new tasks via a few gradient steps. You continue training on the support set rather than freezing the model.
MAML finds model parameters that adapt quickly when fine-tuned on new tasks. It uses two nested optimization loops:
- An inner loop adapts to individual tasks via gradient descent on support sets
- An outer loop updates initialization parameters based on query set performance across many tasks
MAML achieved 63.1% on miniImageNet 5-way 5-shot. The method works across vision, NLP, and robotics, but requires gradient computation at test time, making inference slower than metric-based approaches.
LEO addresses MAML’s limitation with deep networks. Fine-tuning millions of parameters from 5 examples causes overfitting. LEO optimizes in a low-dimensional latent space instead, then decodes to full parameters, achieving 77.6% on miniImageNet 5-way 5-shot.
Meta-transfer learning combines pre-training with meta-learning. Pre-train a deep network on base classes, freeze most layers as a feature extractor, then meta-learn only the final classifier.
This balances sophistication with simplicity, making it practical for production systems.
Transfer learning approaches
Recent research we mentioned earlier showed simple transfer learning can match complex meta-learning on standard benchmarks. The approach looks like this:
- Pre-train on ImageNet
- Extract features
- Normalize with L2
- Classify via nearest centroid
This works because ImageNet features already capture texture, shape, and color patterns. Transfer learning succeeds when you have pre-trained models for similar domains and test classes resemble training classes visually.
However, it fails with large domain shifts or when no suitable pre-trained model exists.
Comparing Few Shot Learning Approaches in Machine Learning
The machine learning algorithm you choose depends on whether you have pre-trained models available, can tolerate slow inference, and need maximum accuracy versus simplicity.
| Method | miniImageNet 5-way 5-shot | Inference | Complexity | Use When |
| Prototypical Networks | 68.2% | Fast | Low | Need interpretability, fast deployment |
| TADAM | 76.7% | Fast | Medium | Want high accuracy, metric-based |
| MAML | 63.1% | Slow | High | Need cross-domain flexibility |
| LEO | 77.6% | Slow | High | Deep networks, maximum accuracy |
| SimpleShot | 81.5% | Fast | None | Have pre-trained model for domain |
Start with SimpleShot if you have a pre-trained model. Move to TADAM for metric-based meta-learning if transfer learning underperforms. Use LEO only when you need maximum accuracy with deep networks and can tolerate implementation complexity.
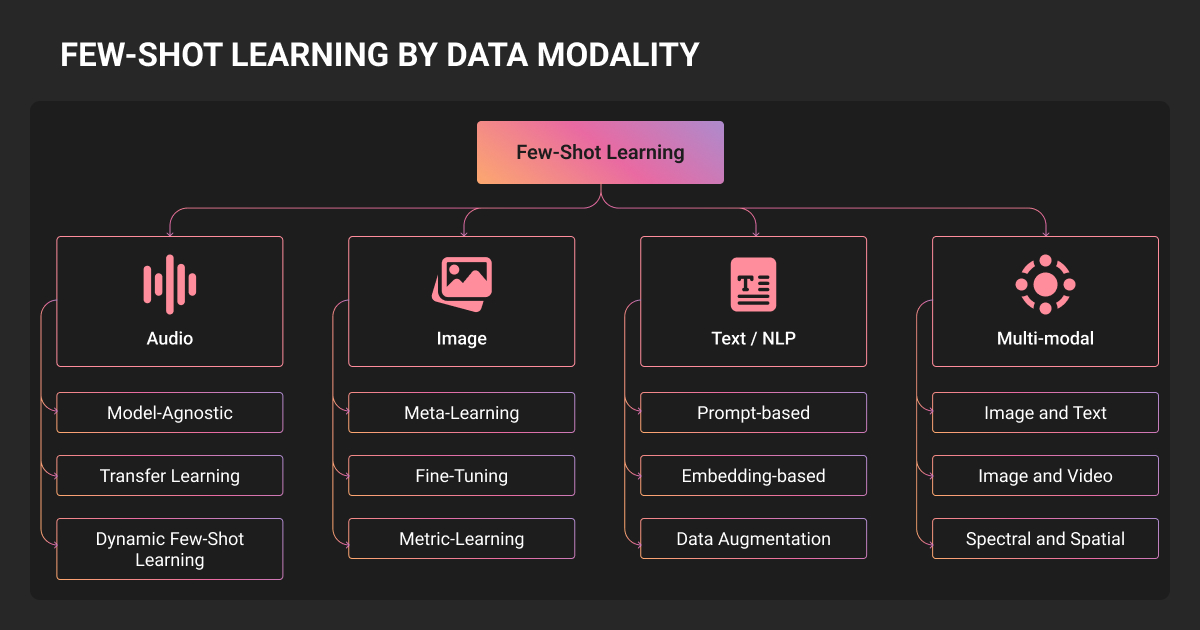
Real-World Applications and Few-Shot Learning Examples
Computer vision
Few shot learning image classification is widely used in manufacturing quality assurance for rare defect detection where new defect types emerge faster than you can collect thousands of examples.
Medical imaging applies FSL when rare diseases have limited confirmed cases. Satellite monitoring uses FSL for time-sensitive detection of events like oil spills where labeled data are sparse but detection speed matters.
Retail companies classify new product arrivals weekly without retraining entire catalog classifiers, handling long-tail SKUs that appear infrequently.
Natural language processing
Chatbot platforms use FSL to add new intents from few example utterances without full retraining. Text classification achieves results comparable to fine-tuning on thousands of examples by using sentence transformers with contrastive learning on fewer than 10 examples per class.
Other domains
Recommendation systems handle cold-start items where user interaction data is naturally limited. Robotics enables learning new manipulation tasks from single demonstrations by meta-learning across related tasks.
Few Shot Learning Challenges and Limitations
Domain shift
FSL models trained on natural images drop significantly in accuracy when tested on completely different domains like medical scans or satellite imagery. Meta-learning learns domain-specific patterns, so what works for natural images doesn't transfer to specialized domains without domain-specific pre-training.
Task mismatch
Training on 5-way 5-shot but testing on 10-way 1-shot causes accuracy drops. Models overfit to specific N and K values during meta-training. If you know test conditions (always 3 defect types, always 10 examples), train on exactly that. If conditions vary, train on diverse task configurations.
Data quality becomes critical
With thousands of examples, label noise averages out. With 5 examples, a single mislabeled support example significantly degrades accuracy.
This changes data annotation requirements:
- Every support example must be correctly labeled
- Ambiguous boundary cases hurt more than in traditional learning
- Expert annotation becomes necessary, not optional
For specialized domains, crowdsourced annotation introduces too much noise for FSL to handle effectively. Medical imaging, satellite analysis, and manufacturing QA need trained annotation teams like Label Your Data who understand subtle inter-class boundaries.
As an alternative option, using data annotation tools with quality control workflows helps catch errors early as well.
Data Preparation for Few-Shot Learning
Strategic sample selection
Which 5 examples you annotate directly impacts performance. Diversity matters more than redundancy.
Bad support set: 5 similar poses, same background, same lighting. Model learns background patterns instead of class features.
Good support set: Different poses, backgrounds, lighting conditions. Forces model to extract invariant features.
Practical selection strategies:
- Cluster unlabeled data using pre-trained embeddings, sample from different clusters
- Train initial model on 3 examples, query for uncertain examples (active learning)
- Have domain experts pick representative samples
Beyond selecting existing examples strategically, synthetic data generation can complement few-shot learning by augmenting limited support sets.
But keep in mind that synthetic examples work best when combined with real annotated data rather than replacing it entirely.
Why annotation quality matters in few shot learning
Few-shot learning reduces annotation volume but increases quality requirements. The smaller the support set, the more each annotation error impacts your model performance.
Multi-annotator consensus workflows where 3 annotators label the same support examples and only unanimous agreements are kept costs more but proves worthwhile because support set quality determines FSL success.
Pre-annotation with foundation models like CLIP can generate candidate labels ranked by confidence, allowing human reviewers to verify rather than label from scratch, significantly reducing annotation time when the foundation model has reasonable zero-shot performance on your domain.
Working with a data-compliant data annotation company experienced in computer vision ensures annotators understand all these subtle inter-class boundaries.
Expert annotation for specialized domains
Computer vision specialization in satellite imagery, 3D LiDAR, medical imaging, and manufacturing QA requires annotators who understand domain-specific patterns.
Generic crowdsourced workers miss subtle inter-class boundaries that matter for classification accuracy.
Experienced teams delivering high-quality data annotation services, such as Label Your Data, can identify diverse, representative support examples rather than just labeling provided data.
For specialized domains, strategic sample selection combined with high-quality annotation often matters more than the meta-learning algorithm choice.
Our team at Label Your Data provides expert annotation for computer vision optimized for few-shot learning AI workflows. You can rest assured that our annotators understand meta-learning requirements for satellite image annotation, 3D LiDAR object detection, and specialized computer vision domains where support set quality determines production success.
How to Implement Few-Shot Learning Models
Datasets and benchmarks
Standard machine learning datasets for FSL benchmarking include miniImageNet, Omniglot, and tieredImageNet.
miniImageNet is the standard benchmark with 100 ImageNet classes split into 64 train, 16 validation, 20 test classes. Most papers report results here. Use this to validate your implementation before moving to custom data.
Omniglot contains handwritten characters from 50 alphabets, serving as an easier benchmark for validating implementations.
tieredImageNet provides hierarchical class structure ensuring train and test classes are semantically distant, making it harder than miniImageNet and better for testing generalization.
Code libraries
- learn2learn provides PyTorch implementations of MAML, Prototypical Networks, and Matching Networks with good documentation
- Torchmeta offers meta-learning datasets and task samplers
- SetFit handles text classification with few examples
Getting started
Baseline your problem by training simple logistic regression on your few-shot data.
If baseline accuracy is high, transfer learning might suffice. If it’s moderate, FSL will help significantly. If it's very low, classes may not be separable from these features.
Validate on miniImageNet before training on custom data. If your implementation doesn't reach published benchmarks on miniImageNet, it won't work on custom data.
Debugging FSL is hard, so benchmark validation catches implementation issues early.
Collect strategically with 5-10 carefully selected examples per class for support sets and 20-50 examples per class for validation. Also, use active learning loops:
- Label 3 examples per class
- Train FSL model
- Query on unlabeled data
- Label examples where the model is most uncertain
- Retrain
Plus, monitor meta-overfitting by tracking accuracy on both meta-train and meta-validation classes. If train accuracy increases while validation plateaus, reduce learning rate, use more meta-training classes, or add regularization.
Choosing Your Few-Shot Learning Approach
Start with transfer learning if pre-trained models exist for similar domains.
Move to metric-based meta-learning (Prototypical Networks, TADAM) if transfer learning underperforms and you need fast inference. Use optimization-based methods (MAML, LEO) only when maximizing accuracy with deep networks justifies implementation complexity.
FSL reduces annotation volume significantly but increases quality requirements. With 5 examples, each label matters. Strategic sample selection, multi-annotator consensus, and expert annotation for specialized domains become necessary rather than optional.
For production computer vision in various domains, our dedicated teams at Label Your Data provide expert annotation support optimized for few-shot learning.
We always make sure our data experts understand meta-learning requirements and can curate the clean, diverse support sets that determine your FSL success.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is few-shot learning?
Few-shot learning trains ML models to classify new categories from 1-10 labeled examples per class by meta-learning patterns across many small tasks, rather than requiring thousands of examples like traditional deep learning.
What is a few-shot learning LLM?
Few shot learning LLM applications provide 2-10 example input-output pairs in the prompt before asking the model to perform a task. For instance, showing GPT-4 five examples of sentiment classification (text + label) before asking it to classify new text, without any LLM fine tuning.
What is a few-shot learning theory?
Few-shot learning theory centers on meta-learning (learning to learn), where models train across many tasks to extract transferable knowledge. The theory posits that good representations and similarity metrics learned from diverse tasks enable rapid generalization to new tasks with minimal examples.
What is the difference between zero-shot and few-shot learning?
Zero-shot learning classifies categories with no training examples by using semantic information (text descriptions, attributes), while the key difference in zero shot vs few shot learning is training data availability: few-shot learning uses 1-10 labeled examples per category. Zero-shot relies on auxiliary data like class descriptions, few-shot uses actual labeled samples from target classes.
What is a few-shot learner?
A few-shot learner is a model trained via meta-learning to quickly adapt to new classification tasks from minimal labeled examples (typically 1-10 per class), such as Prototypical Networks, MAML, or foundation models like GPT-4 that perform few-shot learning through in-context examples.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.