Object Classification: How It Works, Key Models, and Applications

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What Is Object Classification?
- How Object Classification Works in Machine Learning
- Object Detection vs Classification: Key Differences
- Key Object Classification Models
- Real-World Applications of Object Classification AI
- Object Classification in Video Analytics
- ML Datasets for Object Classification
- Data Annotation in Object Classification: The Performance Bottleneck
- About Label Your Data
- FAQ

TL;DR
- Object classification assigns a category label to an image or object crop and sits at the foundation of nearly every computer vision pipeline.
- Most ML teams fine-tune pretrained backbones rather than designing from scratch, with ResNet and EfficientNet still the defaults for production and edge.
- Training data quality sets the performance ceiling, and 30% label noise can cost a model over 8 percentage points of accuracy.
Every time a self-driving car distinguishes a pedestrian from a traffic cone, or a factory camera flags a defective part, object classification is doing the work. It is one of the most foundational tasks in computer vision.
Understanding it well saves time when choosing between architectures, scoping data annotation work, and avoiding costly mislabeling mistakes down the pipeline.
This guide covers how object classification works end-to-end:
- The full pipeline
- Models worth knowing
- How it fits versus object detection
- Real-world deployments
- How to make a model perform well in production
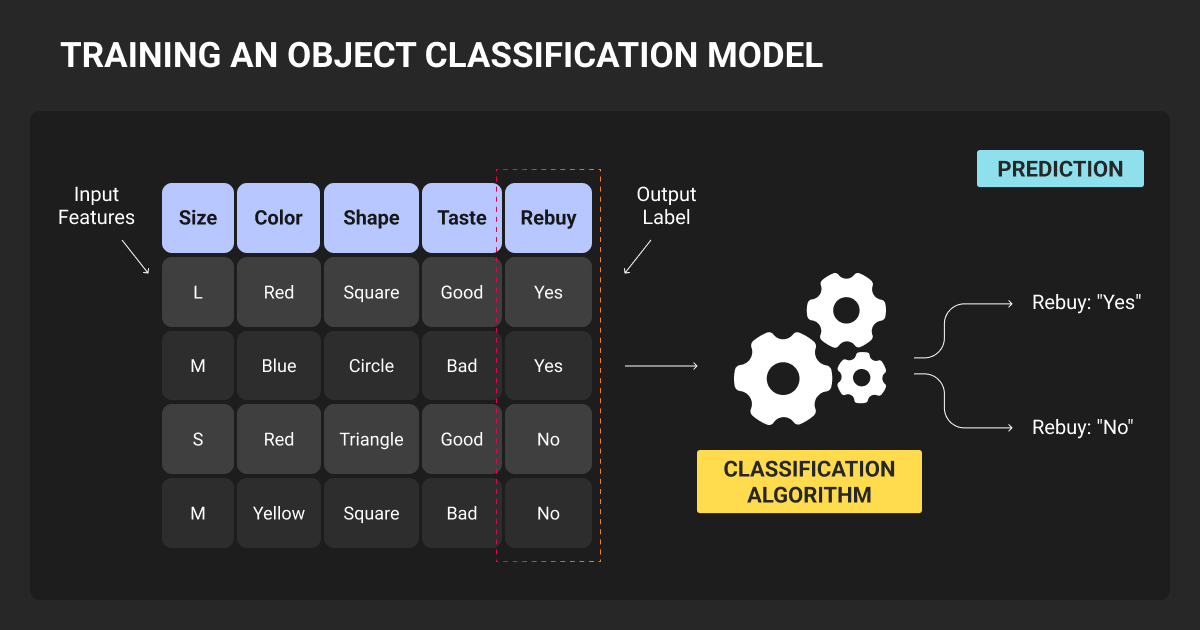
What Is Object Classification?
Object classification assigns a category label to an image, or to a specific region within an image, from a predefined set of classes. The model takes pixels as input and outputs a label (single-label) or multiple labels (multi-label), along with a confidence score for each.
Object classification vs. image classification

The terms are often used interchangeably. The distinction, though, is about what region you are classifying:
- Image classification labels the whole frame
- Object classification labels a cropped region or ROI coming out of a detector or tracker
The two concepts fully overlap when images are already centered on the subject. They diverge when multiple objects appear in a frame, which is where a detector steps in first to isolate regions, and a classifier labels each one.
How Object Classification Works in Machine Learning
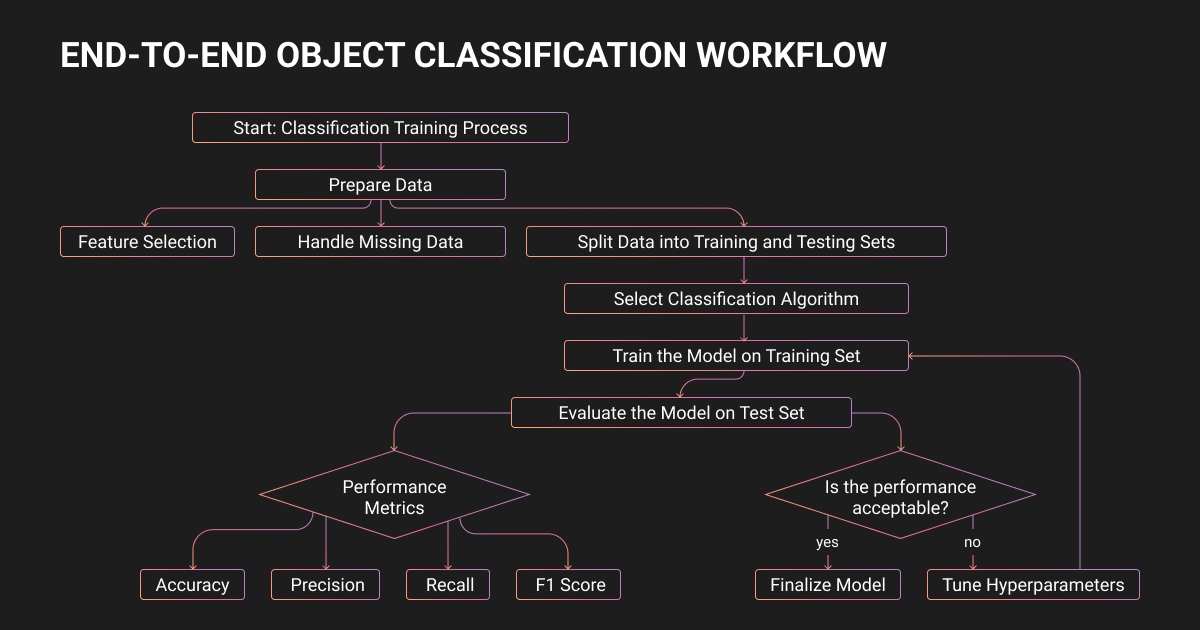
Input preprocessing
Images need to be standardized before model training:
- Resized or cropped to a fixed resolution (224x224 for most ResNet and EfficientNet variants)
- Normalized using per-channel mean and standard deviation
- Augmented with random crops, horizontal flips, and color jitter
Augmentation is a primary reason why object classification models trained on limited data still generalize.
Feature extraction
Feature extraction turns pixels into a representation that separates classes. Before deep learning, the go-to machine learning algorithm for classification was an HOG-SVM or Bag-of-Visual-Words pipeline.
Modern systems learn features end-to-end: CNNs capture local-to-global visual patterns through convolution and pooling, while Vision Transformers split images into fixed-size patches and learn cross-patch relationships using self-attention.
Classification layer and output
The classification head maps learned features to class scores (logits), then applies softmax to produce a probability distribution over all classes.
For multi-label tasks, sigmoid activations replace softmax so each class is scored independently. Training optimizes cross-entropy loss through backpropagation on labeled data examples.
Evaluation metrics beyond accuracy
Overall accuracy is the starting point, but rarely enough. Production systems need per-class precision, recall, and F1, especially under class imbalance.
Calibration matters too: overconfident models produce confidence scores that do not reflect real accuracy, and temperature scaling is a standard lightweight fix.
Robustness under corruptions (blur, noise, weather) is tracked using benchmarks like ImageNet-C as a proxy for real-world distribution shift.
Class imbalance in object classification is the rule, so we treat it as a design constraint from day one. We typically combine three approaches: modest oversampling of minority classes, loss-level techniques (class weighting or focal loss), and threshold tuning per class based on the business cost of false positives vs. false negatives.

Object Detection vs Classification: Key Differences
Classification tells you what category an image or region belongs to. Detection tells you what is present and where, returning (class, bounding box) pairs from a single forward pass.
Think of object detection as classification plus localization, where localization is learned as a regression over box coordinates. Yet, the practical difference between object detection vs classification comes down to data annotation pricing and failure modes.
Object classification AI needs image-level labels, which are faster and cheaper to produce. Detection needs bounding boxes, which introduce edge cases around occlusion and truncation, and uses IoU-based metrics like mAP instead of accuracy and F1.
- Classification is more sensitive to background shortcuts
- Detection adds sensitivity to localization errors in crowded scenes
Many production systems use detect-then-classify: localize objects, crop them, then pass each crop to a classifier. This works well when your taxonomy is fine-grained but spatial isolation of the object is still needed.
For a full breakdown of both tasks side by side, see our guide on image classification vs object detection.
Key Object Classification Models
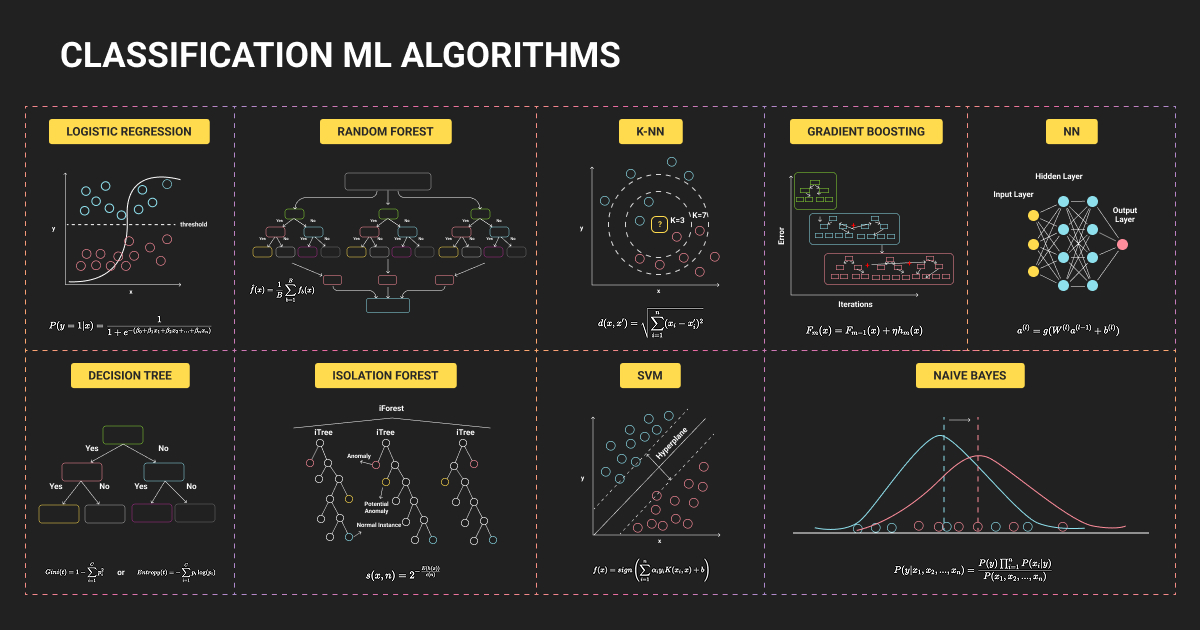
Traditional approaches
HOG-SVM and Bag-of-Visual-Words pipelines dominated before 2012. They still have a place in very constrained compute environments, but they underperform modern pretrained models on almost every natural image problem.
Deep learning architectures
- AlexNet: The first large CNN at ImageNet scale. Dropped top-5 error from ~26% to ~15% and established deep learning as the default approach.
- VGGNet: Pushed depth with 3x3 convolutions. VGG-16/19 became standard transfer learning bases, though 138M parameters make inference expensive.
- ResNet: Residual connections solved the vanishing gradient problem. ResNet-50 (25.6M parameters) remains one of the most widely used backbones in production.
- EfficientNet: Compound scaling across depth, width, and resolution. EfficientNet-B0 hits 77.1% top-1 on ImageNet with just 5.3M parameters. EfficientNetV2 is a strong default for edge and real-time deployments.
- Vision Transformer: Patch embeddings plus transformer encoders. Underperforms CNNs on mid-size datasets but matches or exceeds them with large-scale pretraining.
Foundation models
Most machine learning teams in 2026 select and adapt a pretrained backbone rather than designing one. CLIP-style models enable zero-shot classification by aligning images with text, useful when your taxonomy changes frequently.
DINOv2, Meta’s self-supervised encoder trained on 142M curated images, achieves around 84% top-1 on ImageNet with just a linear classifier on top, no fine-tuning needed.
For edge and mobile, MobileNetV3 is the default (5.4M parameters, 75.2% top-1). For general production use, EfficientNetV2 or ResNet-50 with transfer learning covers most cases.
The three big mistakes I see when deploying object classification models are: training and test data not matching real-world production data, no monitoring for drift after launch, and treating the model as done instead of planning a continuous feedback loop where misclassifications feed back into the training set.

 Co-founder & CEO, AI therapy
Co-founder & CEO, AI therapy
Real-World Applications of Object Classification AI
Autonomous vehicles
Traffic sign recognition, scene classification, and entity-level classification (pedestrian, cyclist, vehicle type) are all object classification artificial intelligence tasks inside the broader perception stack. Modern systems pair CNN backbones with transformer components for multi-modal scene understanding.
Medical imaging
Classification covers disease detection from X-ray, CT, and MRI, outputting diagnostic categories like findings present or absent and severity grade. Expert medical image annotation is non-negotiable since label errors translate directly into diagnostic errors.
Retail and e-commerce
Large catalogs need automated category tagging, attribute classification, and visual search. At scale, teams use weak supervision from search logs because manually labeling millions of SKUs is not practical. Google Lens processes approximately 20 billion visual searches per month.
Security, surveillance, and people and object classification
Surveillance pipelines combine detection with classification: detect entities, track them across frames, then classify each track (person, vehicle, unknown object) or event type (loitering, crowd anomaly).
The 2024 Paris Olympics used AI-powered video surveillance to flag predefined events in real time, illustrating both the scale of these deployments and the governance questions they continue to raise.
Agriculture, geospatial, and manufacturing
Plant disease classification and satellite-based land use mapping both rely on object classification AI models and require custom datasets because public benchmarks do not represent these visual domains.
In AI-powered manufacturing, visual inspection classifiers output defect categories at the component level, with CNNs the established baseline across the industry.
The biggest mistake teams make with object classification is assuming that a good offline score means a good production outcome. They skip drift monitoring, ignore calibration, and fail to test the model under real latency constraints.
 CEO, AI Monk Labs
CEO, AI Monk Labs
Object Classification in Video Analytics
Video classification extends image classification into the time dimension, adding ambiguity from occlusion and motion blur but also useful signal from temporal context.
Three model patterns dominate:
- I3D-style 3D CNNs extend convolutions into the temporal dimension
- SlowFast uses two pathways for semantics and motion at different frame rates
- Video transformers like TimeSformer apply attention across space and time jointly
In live feed systems, the standard pipeline is to detect, track, then classify each track or event. Per-frame classification without tracking produces unstable labels and misses context.
Real-time targets are typically 15 to 30 FPS with latency under 100ms. On edge devices, INT8 quantization delivers roughly 2 to 4 times faster inference with under 2% accuracy loss, and tools like NVIDIA TensorRT reduce latency further.
ML Datasets for Object Classification
| Dataset | Images | Classes | Annotation type | Best used for |
| ImageNet-1K | 1.28M | 1,000 | Image-level labels | Pretraining, benchmarking |
| CIFAR-10 / CIFAR-100 | 60K | 10 / 100 | Image-level labels | Rapid prototyping |
| Caltech-101 | ~9K | 101 | Image-level + outlines | Academic baselines |
| Open Images V7 | 9M+ | 20,638 | Labels, boxes, masks | Multi-task datasets |
| Custom domain data | Varies | Varies | Task-specific | Production deployment |
ImageNet-1K is the standard pretraining source and benchmark. CIFAR-10/100 are fast to iterate on and widely used for ablations. Open Images V7 covers classification, detection, and segmentation in one place, useful for teams working across tasks.
Custom machine learning datasets become necessary when your visual domain differs from web photos. Building them at scale requires a reliable data annotation company to manage labeling consistency across large batches.
Data Annotation in Object Classification: The Performance Bottleneck
Architecture gets most of the attention, but the real performance ceiling is training data quality.
Pervasive label errors exist across major benchmark test sets, including ImageNet validation, meaning model rankings based on benchmark scores alone can mislead.
In controlled experiments, 30% label noise caused accuracy drops of around 8.5 percentage points alongside calibration degradation that makes confidence scores unreliable.
The three annotation challenges that hit teams hardest:
- Class ambiguity (annotators disagree on category boundaries)
- Class imbalance (rare classes get underrepresented)
- Annotator inconsistency (the same image gets different labels across reviewers)
For video data, these issues compound across frames, and without a solid data annotation platform, they rarely get caught before training.
Solving them is about a well-designed process, which is often provided by professional data annotation services. They cover detailed labeling guidelines with visual examples, gold-standard QA checks, inter-annotator agreement tracking, and feedback loops that surface systematic errors early.
Human-in-the-loop workflows, where model-assisted pre-labeling is reviewed and corrected by humans, reduce cost without sacrificing consistency.
About Label Your Data
If you are building or scaling a classification dataset and running into edge cases or consistency gaps, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is an example of object classification?
A quality-control camera captures a cropped image of a manufactured part and a classifier outputs one of several labels: OK, scratch, misalignment, or wrong component. This is a standard image-level classification task applied to an object crop, and it is one of the most common real-world deployments of object classification machine learning.
What is the object of classification?
The target entity being categorized: either the entire image or an extracted region. In detection pipelines, the classifier is applied to localized crops after the detector provides the bounding box.
What is object classification in video analytics?
Classification applied over time to frames, clips, or tracked objects to produce labels like vehicle type, person activity, or event category. Production pipelines chain detection, multi-object tracking, and a secondary classifier per track.
Common model families include I3D-style 3D CNNs, SlowFast, and video transformers like TimeSformer.
What is the object classification method?
Preprocess inputs, extract features with a CNN or transformer encoder, map features to class scores with a classification head, and train end-to-end using cross-entropy loss and backpropagation on labeled data. In 2026, most teams start from a pretrained checkpoint and fine-tune rather than training from scratch.
How to determine object classification?
- Define your class taxonomy before touching any data
- Collect and label images for each class with consistent annotation guidelines
- Preprocess inputs: resize, normalize, and augment
- Train a classification model (ResNet, EfficientNet, or a pretrained backbone fine-tuned on your data)
- Evaluate using per-class precision, recall, and F1, not just overall accuracy
- Monitor for drift after deployment and retrain when real-world distribution shifts
When should you use object classification instead of object detection?
Use object classification AI when images are centered on one subject, when you need a single label per image or crop, and when annotation budget is limited. Use detection when multiple objects appear per frame, when location matters for downstream logic, or when you need per-class instance counts.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.