Semantic Segmentation vs Instance Segmentation: Key Differences Explained

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- How Semantic Segmentation Differs from Instance Segmentation in Practice
- When to Use Semantic Segmentation in ML Projects
- When Instance Segmentation Becomes Essential
- Semantic Segmentation vs Instance Segmentation: Technical Comparison
- Choosing Between Instance Segmentation vs Semantic Segmentation for Your Pipeline
- Implementation and Workflow Tips For Production-Scale Segmentation
- About Label Your Data
-
FAQ
- What is the difference between semantic and instance segmentation?
- When should you use semantic segmentation instead of instance segmentation?
- Why is instance segmentation more complex than semantic segmentation?
- Can you combine semantic and instance segmentation?
- How much does segmentation annotation cost?

TL;DR
- Choosing between semantic vs instance segmentation defines how your model interprets a scene – one captures context, the other focuses on object precision. The wrong choice can mean redoing your entire dataset.
- Semantic segmentation works best for mapping or surface analysis, while instance segmentation is built for counting, tracking, and quality inspection where accuracy matters most.
- The most reliable CV pipelines mix both – semantic models for background context, instance models for per-object precision. Knowing when to combine them separates prototypes from production systems.
How Semantic Segmentation Differs from Instance Segmentation in Practice
Choosing between semantic vs instance segmentation early determines your model’s architecture, data labeling costs, and overall reliability. We’ve seen ML teams burn weeks re-annotating machine learning datasets after realizing that semantic masks can’t distinguish overlapping instances.

Both semantic and instance segmentation fall under the broader field of image segmentation, a cornerstone of modern computer vision.
Semantic segmentation provides a class map for every pixel, while instance segmentation identifies each object individually. That single design choice affects how much compute you’ll need, how long data annotation takes, and how your model interprets complex scenes. In production, many engineers mix both methods or adopt panoptic segmentation to capture context and object identity together.
Decide by the level of detail your project demands:
- Use instance segmentation for counting, tracking, and per-object QA
- Choose semantic segmentation for broader scene understanding and faster inference
Many ML teams still rely on a data annotation company to handle segmentation at scale, especially when projects demand pixel-perfect masks and detailed QA.
When to Use Semantic Segmentation in ML Projects
Use semantic segmentation for context understanding, not object identity.
Semantic segmentation assigns a class label to every pixel in an image, grouping all pixels that belong to the same category (e.g., road, tree, sky, person) into one mask. It focuses on what is in the image rather than how many of each object exist.
This makes it ideal for projects where global context matters more than individual object identity, such as autonomous navigation, medical imaging, or satellite mapping.
Benefits
Semantic segmentation delivers cleaner pipelines, lower compute requirements, and faster inference compared to instance segmentation. It’s efficient for large-scale visual mapping, such as identifying drivable areas, vegetation cover, or tissue structures. In our own labeling experience, semantic maps are also easier to QA consistently at scale because boundaries and class definitions are shared across regions rather than object instances.
Limitations
The same-class merging that makes semantic segmentation efficient also introduces limits. Models fail in dense or overlapping scenes where identical objects touch or occlude one another (a parking lot full of cars, for example, might be interpreted as one large object). This issue becomes especially costly when downstream tasks depend on counts or per-object tracking.
When Instance Segmentation Becomes Essential
Instance segmentation is slower and costlier, but indispensable for precise object-level reasoning.
This segmentation type identifies and separates every individual object in an image while still classifying each pixel. It merges the goals of object detection and semantic segmentation, producing a unique mask for each detected instance (like labeling every car in a parking lot separately rather than merging them into a single “car” region). This method is critical when your model needs to count, track, or analyze individual objects within a shared class.
Why it’s harder but more precise
Unlike simple image recognition, segmentation requires labeling every pixel, not just classifying whole images. Models used for instance segmentation, such as Mask R-CNN or YOLACT, demand heavier architectures, larger datasets, and higher compute budgets. The gain is precision: per-object masks enable metrics like object count, area, and motion tracking that semantic segmentation can’t provide.
Each segmentation machine learning algorithm, from U-Net to Mask R-CNN, balances accuracy, speed, and compute in different ways. We’ve seen teams underestimate the jump in annotation time: every object, even similar ones, needs a separate mask. That precision, however, is what enables robust analytics in production systems.
Real-world use cases
Instance segmentation is essential wherever object-level accuracy drives results. In autonomous vehicles, it distinguishes moving cars from the background. In AI-powered healthcare, it isolates individual cells or lesions. In industrial inspection, it detects product defects across complex surfaces. These applications rely on the granularity of per-object labeling to make accurate decisions in real time.
Extending instance segmentation to video segmentation dramatically increases annotation workload, as each object must be tracked consistently across frames.
If your goal is object-level tracking or identification, instance segmentation is the only reliable option. It’s heavier to run and train, but essential when your model needs to distinguish and follow individual items like cars, products, or tools. Semantic segmentation handles overall scene context, but it can’t replace object-level awareness.

A modern data annotation platform can streamline segmentation workflows by combining automated pre-labeling with targeted human review.
Semantic Segmentation vs Instance Segmentation: Technical Comparison
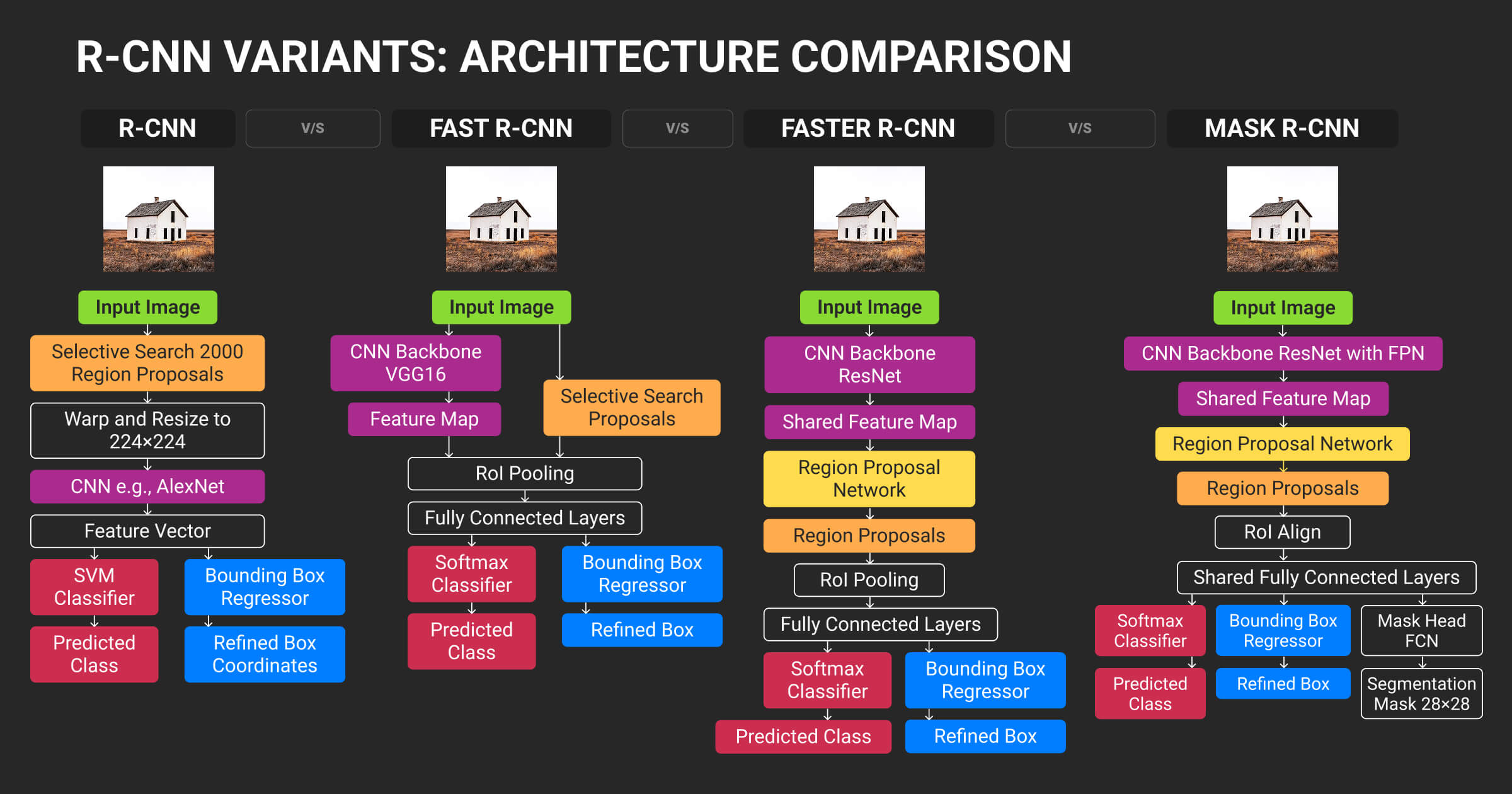
At first glance, semantic and instance segmentation seem like two versions of the same computer vision task: both assign pixel-level labels. The difference lies in what those labels represent and how the models reason about them.
- Semantic segmentation answers what classes are present
- Instance segmentation answers how many separate objects of each class exist
That subtle distinction completely changes how you train, annotate, and deploy models.
| Aspect | Semantic Segmentation | Instance Segmentation | Example Use Case |
| Goal | Assign a class to every pixel | Assign a class and unique ID to every object | Cityscapes (road vs. sidewalk vs. building) |
| Output | One mask per class | Distinct mask for each object instance | Counting cars in a traffic jam |
| Architecture | FCN, DeepLab, SegFormer | Mask R-CNN, YOLACT, SOLOv2 | — |
| Compute Cost | Lower | Higher due to dual detection + segmentation | — |
| Annotation Effort | Moderate: single-class masks | High: per-instance boundaries | — |
| Handles Overlap | No | Yes | — |
| Best For | Scene understanding, mapping, background parsing | Tracking, counting, per-object analytics | — |
Key differences in model design
Semantic segmentation models (e.g., DeepLabV3+, SegFormer) treat the task as dense pixel classification: predicting one class per pixel without distinguishing instances. They perform best when context matters more than individuality, such as road mapping, agricultural monitoring, or tissue segmentation.
Instance segmentation combines object detection and mask prediction, using architectures like Mask R-CNN or YOLACT. These models first locate bounding boxes, then generate precise per-object masks. This added precision allows object counts, shape analysis, and motion tracking, but at a higher computational cost.
Annotation and QA impact
From a data standpoint, instance segmentation multiplies annotation workload. Each object of the same class must be outlined individually, increasing both time and human QA requirements.
In semantic tasks, a single polygon per class region suffices. This explains why large-scale projects, such as autonomous driving datasets, use hybrid pipelines: semantic segmentation for static background elements (roads, sidewalks, vegetation) and instance segmentation for moving entities (vehicles, pedestrians).
Practical takeaway
Semantic segmentation is efficient, interpretable, and cost-effective for global scene understanding. Instance segmentation delivers detailed, per-object insight but requires greater compute, annotation time, and QA oversight. Most mature ML pipelines mix both approaches: semantic for context, instance for decision-critical precision.
The real difference between semantic and instance segmentation lies in the level of granularity you need. Semantic segmentation gives you general scene understanding, while instance segmentation separates every object for counting or tracking. The trade-off is simple – more precision means more data, compute, and annotation work. Choose based on your project’s goals and available resources.

Choosing Between Instance Segmentation vs Semantic Segmentation for Your Pipeline
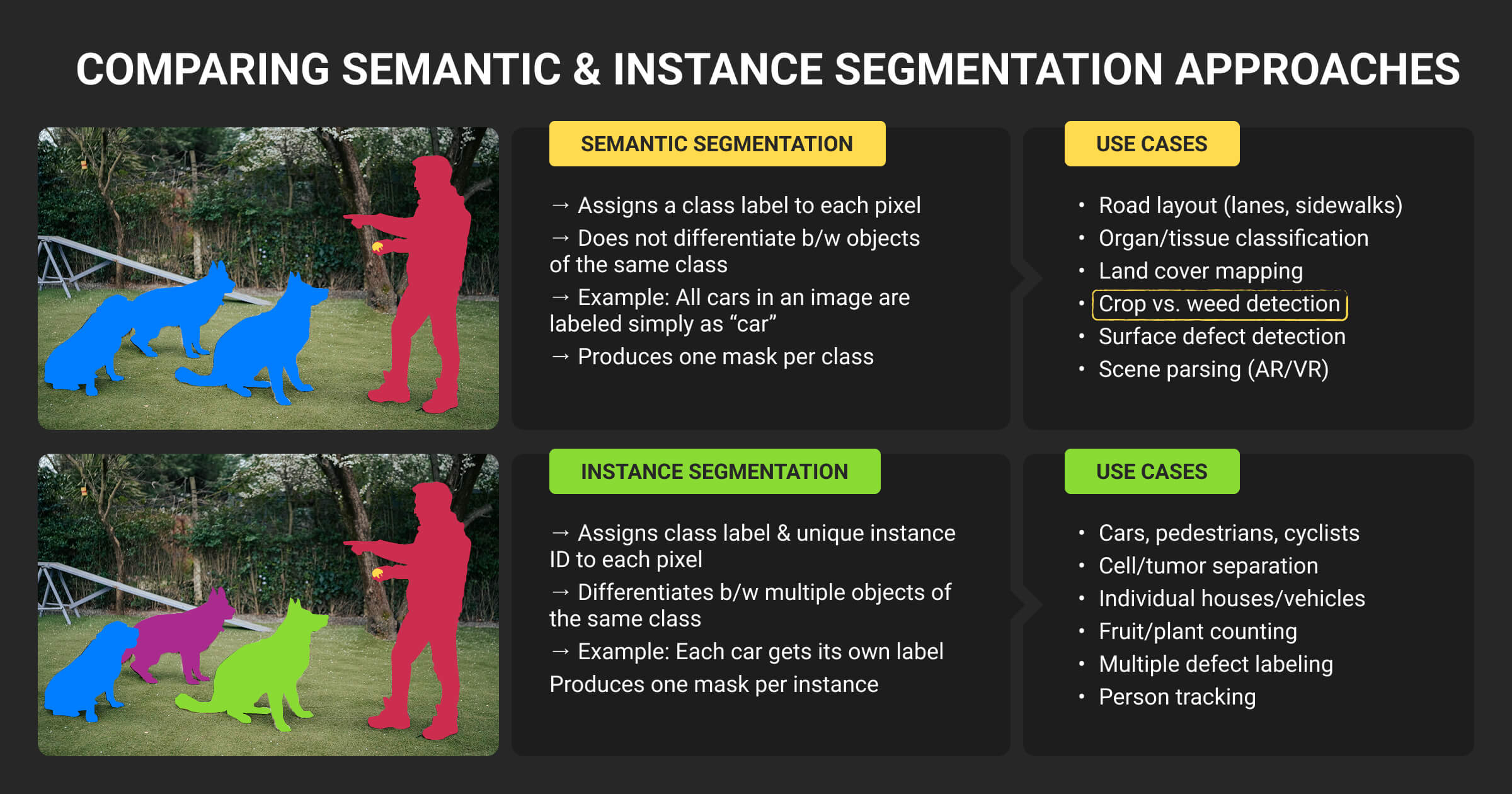
The decision between semantic and instance segmentation ML should be driven not just model preference. For ML engineers, the goal is to match:
- Task precision
- Dataset constraints
- Deployment context
Choosing wrong early means rebuilding your data and model architecture later.
Match model output to downstream task
Start with the end use. Use semantic segmentation when the goal is to map surfaces or classify pixels by type, such as drivable area detection, land cover mapping, or cell-tissue boundaries. Use instance segmentation when your system depends on object-level analytics, like counting vehicles, segmenting tumors, or measuring defect sizes in manufacturing.
If your model’s decisions depend on “how many” or “which object,” semantic masks won’t suffice.
Use data and label strategy as your guide
Check your dataset’s density and variety before choosing:
- For highly structured environments (roads, crops, organs), semantic segmentation scales well
- For dense, cluttered scenes, instance segmentation is mandatory to avoid merged or lost instances
Hybrid pipelines use semantic segmentation to map static background and instance segmentation for foreground entities that move or interact (pedestrians, vehicles, surgical tools).
Estimate labeling cost early
Instance segmentation increases annotation time by 3-5x compared to semantic segmentation. Each object needs its own polygon or mask, which requires specialized QA and version control. Teams using automated tools like Segment Anything still rely on human validation for precise boundaries, especially in overlapping or transparent regions. Underestimating annotation time and budget is one of the top reasons production models stall.
Many ML teams outsource segmentation to specialized data annotation services to balance quality, cost, and turnaround time.
Consider inference context and latency limits
Semantic models (e.g., SegFormer, DeepLabV3+) can infer in real time on edge GPUs or embedded devices. Instance segmentation (e.g., Mask R-CNN, SOLOv2) often requires batch inference or pruning to reach similar throughput.
For embedded or low-latency applications, engineers start with semantic segmentation and selectively fine-tune regions with instance segmentation where precision matters most.
Plan for evolution
Segmentation pipelines rarely stay static. Teams often start with semantic, layer in instance segmentation for precision, and eventually move toward panoptic segmentation as data grows. The key is designing modular pipelines: separate annotation schemas, composable model architectures, and interchangeable output formats. That flexibility saves re-annotation cycles later when requirements expand.
Instance segmentation can easily overwhelm edge devices – it produces far more data per frame and needs stronger hardware and bandwidth. In factories or on embedded systems, teams often default to semantic segmentation simply because their network can’t handle instance-level outputs in real time. Always assess your data pipeline limits before deciding – the best model is useless if your infrastructure can’t support it.

 Business Development and Digital Marketing, Dewesoft
Business Development and Digital Marketing, Dewesoft
Treat the choice between instance segmentation vs semantic segmentation as an engineering decision too, not only as a labeling task. Benchmark small samples under both settings: measure annotation hours, GPU time, and model accuracy on downstream metrics like IoU or F1.
The version that delivers stable, explainable masks with acceptable latency is the one that fits your pipeline best.
Implementation and Workflow Tips For Production-Scale Segmentation
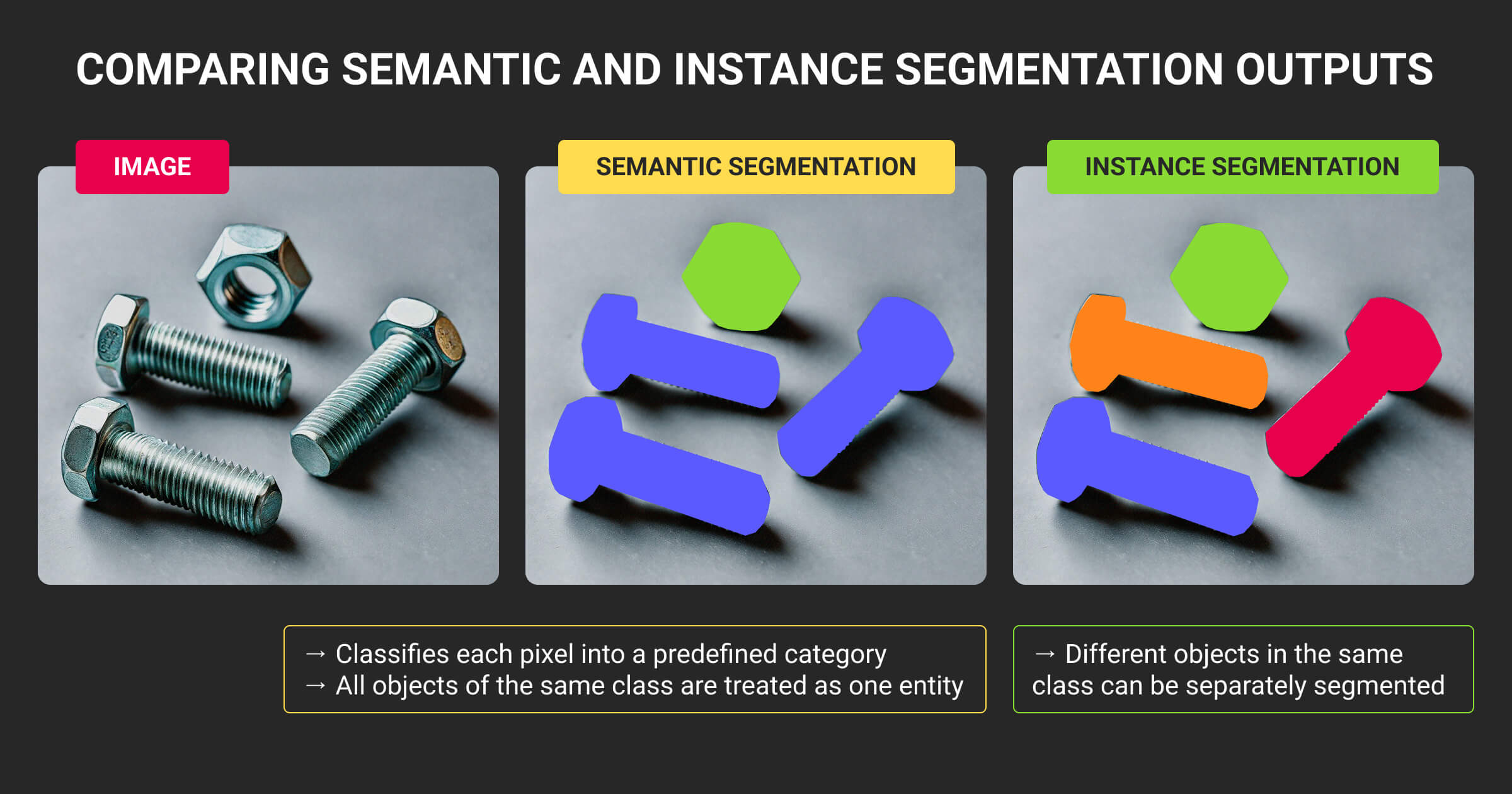
Once your segmentation type (instance vs semantic segmentation) is chosen, the next challenge is keeping models stable, data consistent, and annotation costs predictable.
In practice, most failures in computer vision projects don’t come from model architecture. They stem from workflow design, data drift, or inconsistent human QA.
Optimize your annotation workflow early
Set up annotation schemas that reflect your production labels. Semantic segmentation benefits from class hierarchies (e.g., “vehicle - car - taxi”), while instance segmentation needs unique object IDs and consistent mask naming conventions. Use version control for label maps: changing class names mid-project breaks reproducibility.
Integrate automated pre-labeling (e.g., SAM, Grounding DINO) with human-in-the-loop QA. Auto-generated masks can accelerate annotation by 50-70%, but unchecked errors cascade during model training. Teams that layer human review on 5-10% of data typically achieve 20-30% higher intersection-over-union (IoU) stability across epochs.
Track dataset lineage and versioning
Every mask update or schema revision should create a new dataset version. Tools like DVC, lakeFS, or Weights & Biases Artifacts enable full lineage tracking. This is critical for comparing semantic and instance segmentation results under identical conditions or reverting when a new model underperforms. Dataset reproducibility often determines whether your pipeline scales or collapses under audit.
Design models for maintainability, not benchmarks
Lightweight architectures like SegFormer or YOLACTEdge make deployment easier across environments (edge devices, cloud APIs, or local inference servers). Complex models such as Mask2Former may win benchmarks but demand fine-tuned infrastructure, high memory, and precise batch normalization handling.
Engineers deploying across devices prefer a cascade setup: semantic model for background segmentation, instance model for high-priority classes only.
Combine quantitative metrics with human QA
Metrics like mean IoU, AP50, and pixel accuracy measure consistency, but they don’t capture contextual correctness. For example, whether “sidewalk” and “crosswalk” boundaries overlap correctly. Maintain human audits for critical frames or regions, especially for regulated use cases like medical or automotive vision. Even with synthetic or augmented data, humans remain the final checkpoint for semantic integrity.
About Label Your Data
If you choose to delegate any image annotation task, including segmentation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is the difference between semantic and instance segmentation?
Semantic segmentation classifies every pixel in an image into a category, treating all objects of the same class as a single region. Instance segmentation goes further. It detects and separates each object individually within that category. For example, in a traffic scene, semantic segmentation marks all cars as “car,” while instance segmentation distinguishes each one separately.
When should you use semantic segmentation instead of instance segmentation?
Use semantic segmentation when the task requires understanding what is present in a scene rather than how many objects exist. It’s ideal for large-scale mapping, medical tissue analysis, or road surface detection, where object identity is less important than overall structure.
Why is instance segmentation more complex than semantic segmentation?
Instance segmentation combines object detection and pixel-level classification, requiring models like Mask R-CNN or SOLOv2. This means more computation, longer training times, and higher annotation costs, since each object must have its own mask. However, it’s essential when you need per-object tracking or counting, such as for autonomous vehicles or quality inspection systems.
Can you combine semantic and instance segmentation?
Yes. The combination is known as panoptic segmentation: it merges both approaches to classify every pixel while maintaining individual object boundaries. Panoptic segmentation is commonly used in advanced robotics, urban scene understanding, and autonomous driving systems.
How much does segmentation annotation cost?
Costs depend on complexity and precision requirements. Semantic segmentation typically costs less because masks are coarser and faster to produce. Instance segmentation can cost three to five times more, since annotators draw and verify masks for each object. Using hybrid automation plus human-in-the-loop QA helps balance quality with budget efficiency in large projects.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.