Physical AI: How Machines Perceive and Act in the Real World

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- Physical AI is where machines stop predicting words and start moving real objects, and lab-perfect models still freeze on the first glare or odd angle.
- The hard part was never the model, since robots can’t learn from the internet and real-world sensor data has become the scarcest input in embodied AI.
- Reliable systems come from the messy, multi-sensor data behind perception, which is exactly where most teams quietly fall behind.
A perception model can score 95% on the benchmark and still freeze the first time it meets a rainy intersection or a pallet stacked at an angle the training set never saw. That gap between lab accuracy and real-world behavior is the whole story of Physical AI.
Here is how machines learn to perceive and act in the physical world, and why high-quality AI training data behind them decides whether they work.
What Is Physical AI?
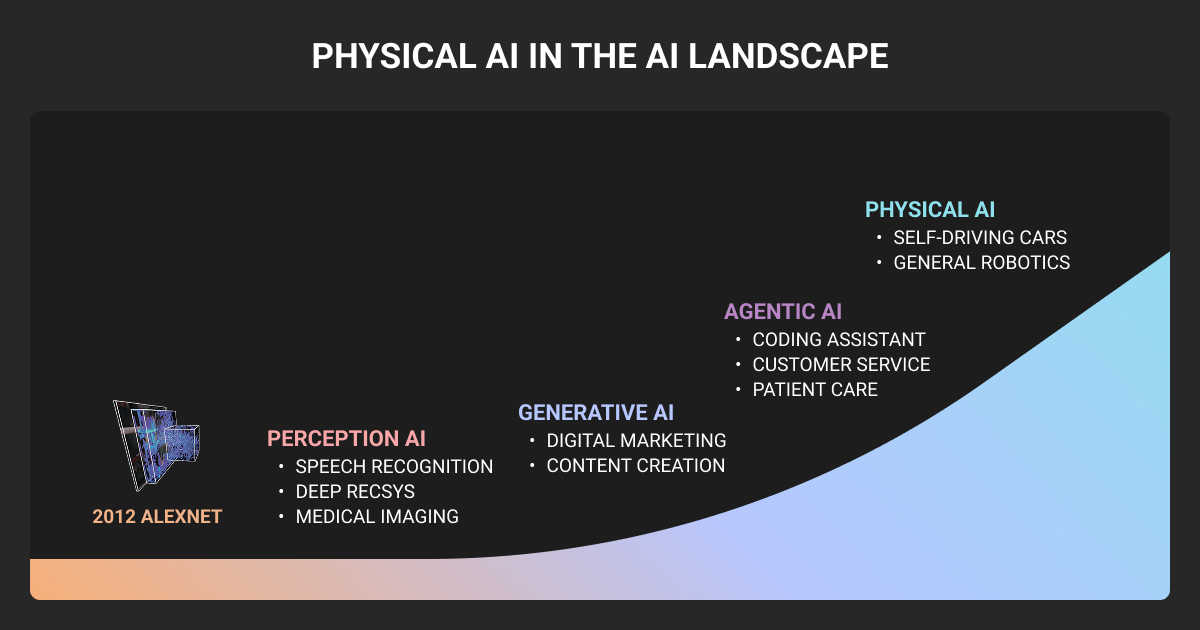
Physical AI is artificial intelligence embodied in machines that sense their surroundings and act on the physical world. It is also called embodied AI.
NVIDIA describes it as the integration of AI into physical systems like robots and autonomous vehicles, so they can perceive their environment and operate within it.
The contrast with conversational AI is simple: a chatbot processes data on a screen; a forklift moves a real pallet in a real warehouse, and a wrong decision has physical consequences.
At NVIDIA’s GTC conference in March 2026, CEO Jensen Huang called this the “ChatGPT moment for robotics,” pointing to models that understand the real world and plan actions inside it. Market analysts valued the physical AI sector at roughly $81 billion in 2025, most of it now shipping into factories and warehouses rather than research labs.
You can see Physical AI taking shape across very different machines:
- Autonomous trucks reading a highway at long range
- Warehouse robots picking from a cluttered shelf
- Delivery rovers crossing a sidewalk full of pedestrians
- Humanoids learning to load a dishwasher
Industrial and warehouse robots are leading the early wave, because the tasks repeat often enough to scale and carry enough value to justify the investment.
If you build robotics or any autonomous system where a model has to act in the world, you are already working on Physical AI. What separates a working system from a demo is the quality of the perception data and data annotation services behind it.
How Embodied AI Maps Perception to Motor Commands
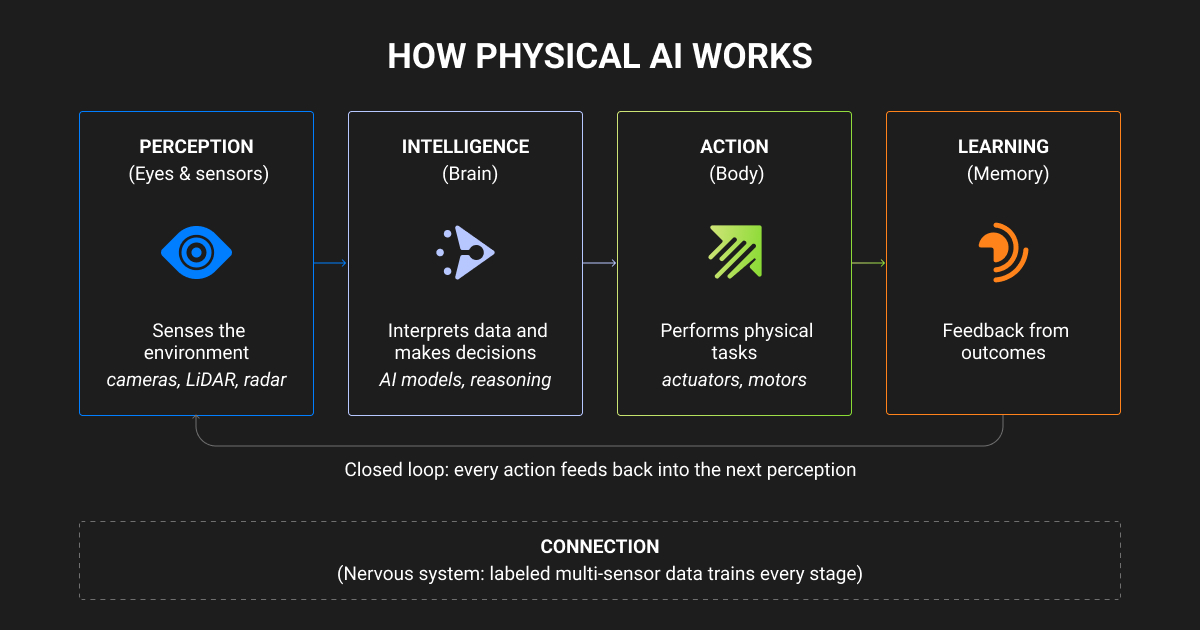
Machines act through a continuous loop: they sense the environment, build an internal model of it, choose an action, then move and observe the result, refining the policy over many iterations.
The loop starts with sensors: cameras, LiDAR, radar, depth sensors, inertial units, and force or torque sensors on manipulators. A perception stack turns those raw signals into structured understanding (i.e., what objects are present, and where they sit and move in 3D space). A policy then maps that understanding to a physical action.
In current systems that policy is often a vision-language-action model that can follow a natural-language instruction and reason about the scene.
Picture a delivery robot approaching a curb. Its cameras and LiDAR see the same scene from different angles, and the perception stack has to decide, in real time, where the curb edge is and whether the moving shape on the left is a pedestrian or a parked scooter. Get the geometry slightly wrong and the robot either freezes or steps into traffic.
Every one of those judgments traces back to how the underlying training data was annotated, which raises the obvious question of where that data comes from.
Why simulation can’t replace real data
Simulation gives you scale, but it cannot reproduce the full distribution of real-world conditions.
Teams train robots in physics simulators like NVIDIA Isaac Sim and generate synthetic scenarios with world models like NVIDIA Cosmos, because collecting real-world data is slow and expensive.
Simulation handles volume well but struggles with the long tail: sensor noise, glare, deformable objects, and people who behave in ways no script predicted. Real labeled data is what grounds a policy and validates it before deployment, which is why simulation-trained systems still need real-world data no matter how good the simulator is.
The trait that separates lab-strong models from production-ready ones is friction. In the lab, datasets are clean and consistent; in the real world, data is full of edge cases and disagreement between annotators. Models trained only on polished data fail the moment they hit ambiguity. Data must mirror the conditions your system will actually operate in.

Ouster, which builds digital LiDAR sensors for automotive and robotics, saw this firsthand: after our team at Label Your Data annotated its LiDAR scans with 2D boxes and 3D cuboids across both static and dynamic sensors, the cleaner training data lifted product performance by 20% and improved the model’s multi-object tracking accuracy by 15%.
Learn about the key differences between synthetic data vs real data in machine learning.
Why Real-World Sensor Data Is the Bottleneck in Physical AI
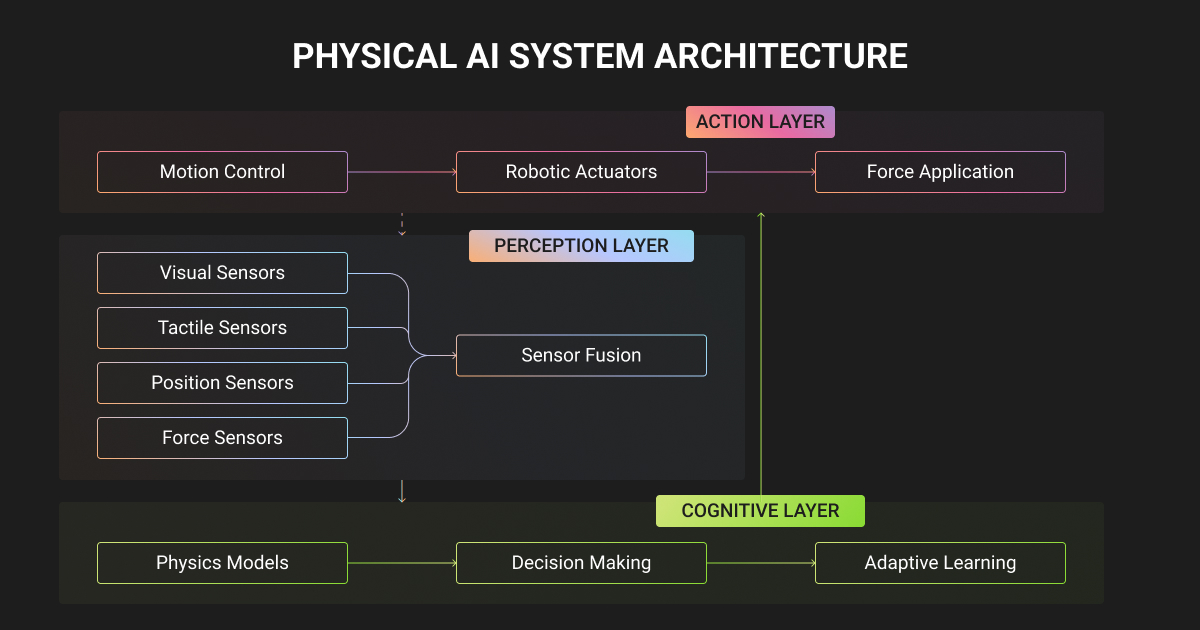
The hard part of Physical AI is getting enough high-quality, real-world sensor data to train and validate it. Real-world interaction data cannot be scraped from the web or generated cheaply at the scale perception models need.
Real-world interaction data has to be physically collected
Language models train on billions of web pages and image models on hundreds of millions of photographs. No equivalent corpus exists for embodied AI, because each example is a physical action that has to be performed and recorded.
The volume gap against language data is several orders of magnitude:
| Training data | Volume collected |
| Google RT-1 (13 robots, 17 months) | ~130,000 trajectories across 700+ tasks |
| Open X-Embodiment (dozens of labs pooled) | ~1 million trajectories |
| A typical language model corpus | billions of examples |
Funding doesn’t remove the data collection cost
More than $6 billion went into humanoid robots in 2025, and the data shortage persisted, because the limiting factor is physical collection, not funding. Companies are now paying to generate it directly: in March 2026 DoorDash launched an app paying couriers to film themselves doing chores as robot training footage.
Collection is only half the problem. A robot placing a part needs time-synchronized, multimodal traces (vision, depth, joint position, or motor command) aligned to the same moment, and annotating those is a fundamentally different task from labeling a single image.
Data Annotation Challenges in Physical AI Models
Embodied AI needs richly labeled, multi-sensor data that captures geometry and motion, in 3D and over time. A flat 2D bounding box rarely tells a machine enough to move safely.
Think about a robotic arm grasping a cup. A box around the cup in a photo says almost nothing useful. The arm needs the object’s pose in three dimensions and the contact points where a grasp will hold. That means depth and 3D geometry working together, captured frame by frame.
In practice, perception teams building real-world systems repeatedly need:
- 3D point cloud and LiDAR cuboids for object position and orientation in 3D space, rather than only on the flat image plane.
- Multi-frame object tracking so a pedestrian or a pallet keeps a consistent identity across an entire sequence.
- Semantic and panoptic segmentation to separate the surfaces a machine can move on from the obstacles it must avoid, at the pixel level.
- Sensor fusion alignment so every sensor stream agrees it is looking at the same object.
- Depth and keypoint annotation for grasping and pose estimation.
- Edge-case curation, the rare and awkward frames where models actually fail.
This is the work that separates a perception system that holds up from one that stalls in the field.
It’s also where a specialist data annotation company earns its keep: NODAR, building 3D depth-perception software for autonomous driving, turned to Label Your Data for around 60,000 polygon masks when its own team couldn’t reach that volume, work that fed the depth models directly and cut validation cycles.
Your data and evaluation sets have to mirror production noise and long-tail distributions, not just clean, curated examples. Models often fail in deployment because the eval set was too clean or missing the hard cases. If you cannot explain where the model fails across each segment, you cannot systematically improve it.

 AI & Data Platform Leader
AI & Data Platform Leader
For a deeper dive, see our complete guide to data annotation, covering the tools, techniques, and best practices for producing high-quality training data.
5 Steps to a Production-Ready Perception Data Pipeline
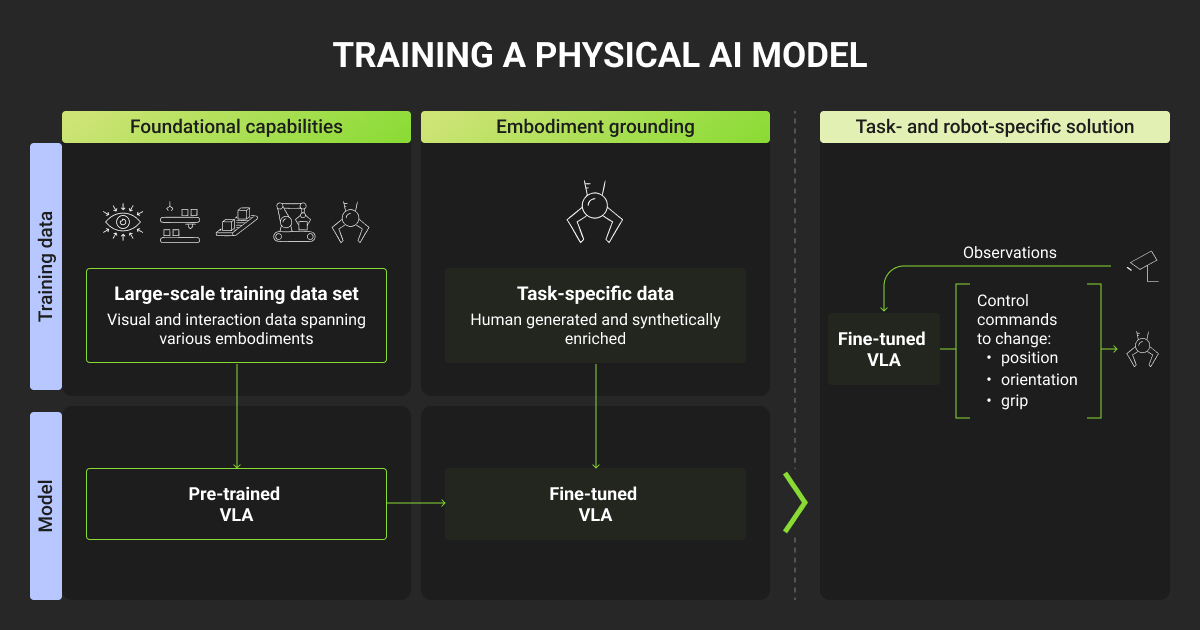
Build your pipeline around the way your model fails in deployment. A high benchmark score will not reveal that. The frames your machine learning model gets wrong in the field are the ones worth your best labeling effort.
Five core steps that consistently pay off:
Step 1: Define label schema around real failure modes
Start from where the model breaks in deployment, then expand outward. A schema designed only for clean benchmark data will miss the cases that matter.
Step 2: Mine edge cases from production logs
Your deployment is generating the rarest, most valuable training data you will ever get. Capture it on purpose.
Step 3: Keep humans in the loop for safety-critical labels
Automated pre-labeling is a great accelerator. On the annotations where a mistake has physical consequences, human annotation QA is what stops a bad label from reaching the model.
Step 4: Enforce cross-sensor consistency
Fused annotations have to agree across modalities and across time, or your model learns from contradictions.
Step 5: Version and audit every dataset change
When a model regresses, you need to trace it back to the exact data that moved.
Teams that build their data pipelines with the same level of care as their model deployment systems tend to have better success in production. On the other hand, teams that view labeling as a secondary task often find themselves repeatedly encountering the same edge cases that their models have already struggled with.
Since labeling deserves that rigor, it’s worth estimating costs upfront. You can do this using our free cost calculator and check the data annotation pricing required for your project.
About Label Your Data
Our team works on the annotation that perception depends on: 3D point cloud and LiDAR labeling, multi-frame tracking, segmentation, and sensor-fusion alignment, delivered through a human-first, AI-enabled model with quality assurance built in.
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is a physical AI example?
A self-driving car is a clear example of physical AI. It senses the road through cameras and LiDAR, then steers and brakes on its own. Other common examples include warehouse robots that pick items from shelves and humanoid robots learning to handle real objects.
What is an embodied AI?
Embodied AI is artificial intelligence that lives inside a physical body, like a robot, and learns by interacting with the real world through its sensors and actuators. Instead of processing data on a screen, it perceives its surroundings and acts on them.
What is the difference between agentic AI and physical AI?
Agentic AI operates in software, autonomously planning and carrying out digital tasks like booking a trip or running a multi-step workflow. Physical AI operates in the real world, where a machine perceives its environment and performs physical actions. A robot can be both at once, using agentic planning to decide what to do and physical AI to actually do it.
What is physical AI vs generative AI?
Generative AI creates content such as text and images by learning patterns from large machine learning datasets, and it works in the digital domain. Physical AI perceives and acts in the real world through machines like robots and vehicles.
What is the difference between Embodied AI and Physical AI?
They’re essentially synonyms. The difference is that embodied AI stresses the intelligence having a physical body, while physical AI (the newer, NVIDIA-popularized term) stresses acting in the real world.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.