Multimodal Annotation: Labeling Data Across Multiple Formats

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- Labels across image, video, text, audio, and 3D data must agree with each other, not just be correct on their own.
- Most multimodal annotation quality failures happen between modalities, not within them, so QA must check across formats.
- Automation speeds up multimodal labeling but trained annotators and domain expertise are what keep labels consistent at scale.
Modern AI systems don’t operate on a single data type.
Autonomous vehicles fuse LiDAR point clouds with camera feeds and radar signals. Retail AI combines product images with text descriptions and customer interaction logs. LLMs now process images, audio, and documents alongside text.
Training these systems demands multimodal data annotation: labeling that connects data types so models understand how an image, its text description, an audio clip, and a sensor reading all describe the same scene.
What Is Multimodal Data Annotation?
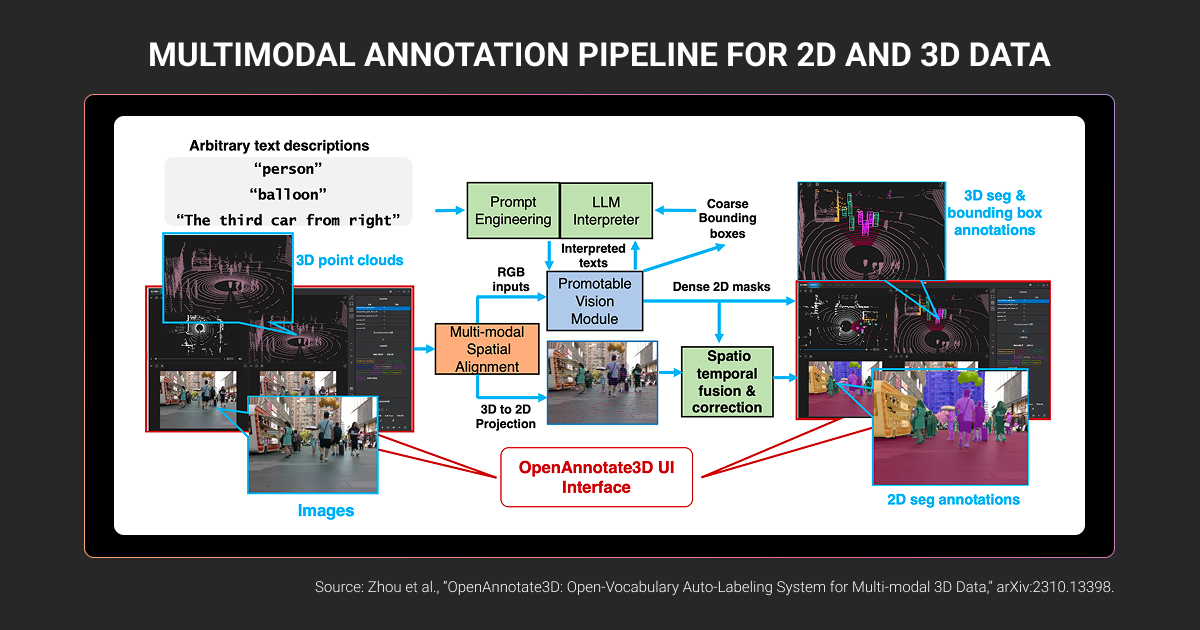
Multimodal data annotation is the process of labeling AI training data that contains two or more data types within a unified workflow. Labels across modalities must be synchronized, consistent, and contextually aligned.
This is what separates it from standard data annotation. In a unimodal project, you label images or transcribe audio independently. In a multimodal AI project, labels need to agree with each other.
For example, a 2D bounding box in a camera frame has to match the 3D cuboid of the same object in a LiDAR scan, captured at the same moment.
Production AI is multimodal by default:
- Models like GPT-5.4 and Gemini 3.1 process text, images, audio, and video natively
- Perception stacks in self-driving cars fuse three or more sensor types
- Recommendation engines pair product photos with text attributes and user reviews
All of these need training data where the relationships between formats are explicitly labeled.
Multimodal data annotation tools provide the workspace for drawing boxes, tagging text, and managing labels. But these tools alone don’t produce consistent labels across different data formats.
Expert data annotators working on multimodal machine learning projects are trained to understand the relationships between modalities. Along with a human-led annotation QA process, they check whether formats agree, not whether individual labels look right in isolation.
The best multimodal data annotation service providers build these human and process layers around whatever tool the client uses, with data annotation pricing structured around project complexity, not just volume.
Understanding Multimodal Data: The Core Modalities
Each data type brings its own annotation techniques and its own headaches.
Image data
Image annotation includes bounding boxes, polygons, semantic segmentation and instance segmentation, and keypoint labeling. The complexity with image datasets lies in occlusion, lighting changes, and class ambiguity at object boundaries. In multimodal projects, image labels often serve as the reference that other modalities align to.
Video data
Video annotation adds a time dimension. Object IDs must persist across hundreds of frames, even through occlusions where an object disappears and reappears. Motion blur and varying frame rates add friction. Video timestamps in multimodal projects become the synchronization backbone for audio and sensor data.
Text and documents
Text and documents require Named Entity Recognition (NER), sentiment analysis, intent classification, and document layout parsing. Domain-specific terminology and multilingual content make the annotation process harder.
But the risk across modalities here is when text captions don’t accurately describe the paired image. This teaches trained models to hallucinate, generating descriptions of things that aren't even there.
Audio data
Audio and speech annotation covers transcription, speaker diarization, emotion recognition, and sound event detection. Overlapping speakers, background noise, and accent variation all increase multimodal annotation difficulty. Even small timestamp drift between audio and video compounds over long recordings.
3D point cloud and sensor data
3D point cloud and sensor data (LiDAR, Radar) is where multimodal annotation gets hardest.
LiDAR returns sparse points, especially at range, and weather like rain adds significant noise to point clouds. Calibration between LiDAR and camera drifts over time from vibration and temperature changes. Plus, a 3D cuboid must correspond exactly to the 2D bounding box of the same object in the camera frame, despite different coordinate systems and capture rates.
These multi-sensor fusion challenges are well documented in autonomous driving research and apply directly to how annotation pipelines must be structured.
Here’s what matters for each data modality, plus the cross-modal challenge it introduces.
| Modality | Key annotation techniques | Biggest cross-modal challenge |
| Image | Bounding boxes, segmentation, keypoints | Misalignment here affects every other modality anchored to it |
| Video | Object tracking, temporal event tagging | Maintaining label IDs across thousands of frames |
| Text | NER, intent classification, relation extraction | Captions must reflect what’s actually in the paired image or video |
| Audio | Transcription, diarization, event detection | Timestamp alignment with video frames; small drift compounds fast |
| 3D Point Cloud (LiDAR) | 3D cuboids, point clouds, fusion alignment | Matching sparse 3D geometry to dense 2D camera data across coordinate systems |
Understanding these modality-specific challenges is the first step. The next is building a labeling process that holds them together.
The Multimodal Data Labeling Process: Best Practices
Multimodal data annotation needs a workflow that enforces consistency across modalities.
Running separate single-modal projects and merging outputs afterward is the most common mistake machine learning teams make. It produces multimodal datasets where labels are individually correct but broken across formats.
Here’s how to correctly structure a multimodal annotation workflow.
Define your taxonomy across all modalities upfront
Define relationships between formats explicitly in your guidelines: every 3D cuboid should have a corresponding 2D box in the matched camera frame. The “pedestrian” label must mean the same thing in 2D image boxes, 3D LiDAR cuboids, and video tracking IDs.
Most inconsistency between data modalities in multimodal projects traces back to vague or siloed annotation instructions.
Synchronize and align data before annotation starts
Before labeling begins, data from all sensors must be aligned in time and space.
Temporal alignment matches timestamps so a LiDAR sweep and camera frame refer to the same moment. Spatial alignment maps data into a shared coordinate system so a 3D point lands on the correct pixel in the camera image. Hardware-level sync (PTP or shared GPS/IMU signals) is most reliable; software interpolation works as a fallback but errors accumulate. At highway speeds, even a small timestamp offset shifts a pedestrian’s position by over a meter.
If the data is misaligned before annotation starts, the labels will be too.
Design workflows around cross-modal context
There are two common strategies you can use:
- Sequential (label the primary modality first, then use those labels to guide the next)
- Parallel (annotators see multiple modalities side by side)
Sequential strategy works when one data modality is dominant. Parallel strategy works when modalities are tightly coupled.
Either way, annotators need domain context. AV annotation requires understanding of driving scenarios, not the ability to draw boxes alone.
Build QA that checks between modalities, not just within
A three-tier structure works well for multimodal labeling process:
- Annotator self-review against guidelines
- Peer review by a different annotator, focused on cross-modal consistency
- Senior QA audit by a domain expert, measuring inter-annotator agreement across modalities
When different teams label different modalities using separate guidelines, quality gaps between formats are inevitable. Expert human-led QA that spans modalities catches these disconnects before they reach your training pipeline.
Accelerate with automation, keeping humans in the loop
Pre-trained models generate initial labels. Active learning routes ambiguous samples to human annotators. Transfer learning bootstraps annotations from one modality to another (e.g., projecting 2D detections into 3D space as starting cuboids).
Automation handles speed, but the multimodal data labeling workforce is what keeps labels accurate for reliable model training.
But even with the right process in place, scaling multimodal annotation introduces its own set of problems.
We run 300+ cameras at a licensed venue, and facial recognition falls apart when stage lighting and hats change between frames. But real-world signal conflicts demand override rules: when Bluetooth, camera, and credentials disagree, we spent months annotating which two-out-of-three combinations the system should trust.

 Managing Director, DASH Symons Group
Managing Director, DASH Symons Group
Overcoming Multimodal Annotation Challenges
Every team scaling multimodal data annotation hits the same friction points. Ignoring them means feeding conflicting labels into your training pipeline.
Consistency across modalities at scale
When separate teams label different formats, interpretation drifts. Misaligned labels in one modality introduce conflicting signal across the fused dataset, and catching it late means re-annotation that doubles timelines.
What works instead: unified annotation protocols from the start, QA expert that validates across formats, and regular calibration sessions where annotators from different teams review the same samples.
Temporal synchronization drift
Sensors run at different clock speeds: LiDAR at 10 Hz, cameras at 30 fps, radar at 20 Hz. Even with initial calibration, drift accumulates on moving platforms due to vibration, temperature, or sensor remounting.
Make sure to validate calibration before each multimodal annotation batch. Build guidelines that instruct annotators to flag suspected sync issues instead of forcing labels onto misaligned data.
Annotator expertise requirements
Multimodal annotation takes significantly longer than single-modality work because annotators carry a higher cognitive load across formats. Data annotation teams need to understand what they’re labeling across formats and why it matters for the multimodal model output.
Crowdsourced annotators trained on a single task type typically lack this context. The answer is hiring dedicated teams at a data annotation company with domain training. They go through a structured onboarding with qualification gates before anyone touches production data.
Among leading multimodal data labeling solutions, the multimodal data labeling services that deliver consistent results are the ones investing in trained, domain-specific annotators.
Scalability without losing mutimodal annotation accuracy
More data volume implies more annotation workforce. And every new hire is a quality risk that compounds across modalities.
What helps here, from our experience at Label Your Data, is tiered human-led QA with gold standard items (pre-labeled samples mixed into the queue) for continuous monitoring.
Automated checks catch structural issues like missing labels, timestamp gaps, and coordinate errors before human QA. When error patterns emerge, feedback loops update guidelines and retrain annotators.
When we deployed AI career coaching to LATAM job seekers, our first model broke because users recorded goals in Spanish but submitted resumes in English. Human behavior upends annotation assumptions across modalities, and we had to re-label 40% of our training set for code-switching patterns.
 Team Principal | Enterprise Growth Partner, Berelvant AI
Team Principal | Enterprise Growth Partner, Berelvant AI
To sum up, the AI training data solutions provider that builds these systems into their delivery model from day one is the one who does the best multimodal data labeling.
Real-World Applications of Multimodal Data Annotation
Autonomous vehicles and ADAS
The automotive sector is the most annotation-intensive multimodal domain.
Camera, LiDAR, and radar data must be labeled with 2D boxes, 3D cuboids, and segmentation masks that all agree for the same objects at the same timestamps. HD maps combine geospatial data with visual imagery and 3D lane markings. Safety validation datasets require scenario labeling of critical driving events across all sensor streams simultaneously.
A single test vehicle generates 1-2 TB of raw data per day. Annotating that volume at production quality takes structured programs, not ad-hoc labeling batches.
Retail AI and e-commerce
Visual search models need labeled dataset pairs where image attributes (color, shape, and pattern) link explicitly to text attributes.
Shelf monitoring combines video feeds with planogram data to detect out-of-stock or misplaced products. Catalog enrichment annotates product photos alongside structured attributes like SKU and category for recommendation engines.
Trust and safety
User-generated content is inherently multimodal: an image, a text caption, and sometimes audio or video. Harmful content often requires understanding across formats. An image that’s benign alone becomes harmful in context of its caption.
Data annotators evaluate the combined meaning, not each modality in isolation. From our trust and safety work at Label Your Data, these programs tend to run long-term, with content policies that evolve and annotation guidelines that must keep pace.
Multimodal LLMs and generative AI
Vision-language models need image-text alignment data: captioning, visual QA, and image-text matching machine learning datasets.
RLHF for multimodal outputs requires human raters who compare responses containing both text and images. Instruction tuning annotations cover multi-step sequences (instruction, observation, reasoning, and action) as complete units. And hallucination detection flags model outputs where text describes objects not present in the image.
Multimodal annotation fails not within a single format, but where formats meet and labels disagree. Getting it right takes trained annotators, QA that catches misalignment across modalities, and domain expertise no tool provides on its own.
About Label Your Data
For teams building multimodal AI systems that need production-grade annotation across image, video, text, audio, and 3D data, Label Your Data provides dedicated annotation teams with quality assurance built into every project.
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
How does multimodal labeling differ from annotating each data type separately?
Separate annotation treats each format in isolation. Multimodal labeling requires that labels agree across formats: a 3D cuboid matches its 2D box, a transcript aligns with the right video frame, and a caption describes what's actually in the image. That consistency requirement is what makes it a different discipline.
What makes cross-modal QA different from standard annotation QA?
Standard QA checks labels within one modality. QA that spans modalities checks whether labels agree between formats: does the 2D detection match the 3D cuboid for the same object? Does the text align with the audio at the correct timestamp? Most multimodal quality failures happen at these seams between formats.
Can multimodal annotation be fully automated?
Not yet. Pre-labeling and active learning speed things up. But consistency checks across formats, ambiguous scene interpretation, and domain judgment still need human oversight, particularly in safety-critical domains like autonomous driving and healthcare, where label errors carry real consequences.
How do you ensure quality in multimodal data labeling?
With expert human-led QA that checks between modalities, not just within them. Per-modality accuracy is baseline. The real quality gate is whether labels agree across formats: does the 3D cuboid match the 2D box, does the transcript align with the video frame.
That requires tiered review, domain-trained annotators, and feedback loops that update guidelines when error patterns emerge.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.